
Это огромный лонгрид, который является текстовой расшифровкой митапа, проведенного мной 19 декабря 2019 года в Типографии. Презентация доступна по ссылке.
Что такое качество?
Вряд ли кто-то удивится, если я скажу, что качество - это залог успешности продукта. Если продукт не качественный, то вряд ли он нужен целевой аудитории, потенциально готовой его купить. Вроде логично.
Но каждый раз, когда поднимается вопрос качества, никто не может дать четкого определения этому термину. Каждый из нас представляет, по каким критериям он будет принимать индивидуальное решение об уровне качества того или иного продукта, но эти метрики остаются очень личными. И очень редко можно быть уверенным в том, насколько качественным может быть тот же самый продукт для другой персоны.
Каждый хочет получать качественный для себя продукт. Приходишь ты в магазин, покупаешь себе батон колбасы за условные 500 рублей. Красивый такой, с крутой надписью «ЭКО» на этикетке. А еще там может быть «Без глютена», или «Без ГМО!» не дай бог. Довольный идешь домой, отрезаешь себе тонкий красивый ломтик, вдыхаешь аромат, откусываешь, кайфуешь. Вкусно! Качественно!
Потом ради интереса решаешь почитать, что там написано на обороте этикетки в составе: мясо кур механической обвалки, растительный белок, Е575, Е621 (он же глутамат натрия), загуститель, краситель, консервант и прочие прелести.
Сначала было все хорошо и качественно до тех пор, пока не обратил внимания на состав. Продукт больше не качественный для тебя лично. И это стало важным фактором при принятии решений о качестве в будущем.
Другой пример. Решил ты сменить свою старенькую зачахлую «девятку» на новенький авто. Поднакопил за последнее время работы в IT аутсорсинге на хорошую машину. Поездил по автосалонам, повыбирал, возможно изучил какие-то характеристики, посмотрел обзорчики на youtube. Определился с маркой и моделью, поехал на тест-драйв авто с логотипом трехлучевой звезды на капоте. Тебе настолько все это нравится, ты в экстазе, получаешь кайф. Ты чувствуешь качественные материалы вокруг себя, видишь как бодро едет авто. Оформляешь кредит, отдаешь все свои деньги на первоначальный взнос и забираешь машинку, катаешься в удовольствие.
Проходит месяц, ты начинаешь изучать более подробно, и узнаёшь, что оказывается на твоем авто стоит трехцилиндровый мотор, и это как бы уже «не очень». Мнения «экспертов» тоже привносят долю волнения, всячески критикуя подобное решение автоконцерна. А еще узнаешь, что этот мотор разработан совместно с другим автопроизводителем, логотип которого в виде ромбика, и ты вспоминаешь, что такие авто «с ромбиком» очень ценятся среди таксистов, как минимум за их дешевизну.
Если бы ты не узнал об этом факте, то так бы и ездил спокойно на своем авто, но ты ведь узнал, и в будущем теперь будешь принимать решения о покупке авто исходя и из этого критерия тоже.
Таких примеров можно привести большое количество. Я уверен, что у каждого из вас были подобные моменты в жизни не один и не два раза. Чем больше таких событий в жизни происходило, тем более грамотным в принятии решения становится человек.
Так вот о чем это я. Качество - это почти всегда очень субъективная штука. Далеко не всегда его можно выразить в виде какой-то абсолютной величины. Качество - относительно. Когда один человек рассказывает о качестве другому человеку, который ничего не знает про предмет разговора, нужно обязательно вводить сравнительную степень, чтобы собеседнику было понятно.
Качество - это отличный двигатель торговли.
Бизнесмены давно уже поняли, что качество - это способ продать бОльшее количество продукции. Если продавать товар, который превосходит по качеству товары конкурентов - можно завоевать бОльшую часть рынка. Да, качество может дорого обойтись, но в долгосрочной перспективе это правильная стратегия. За примерами тут далеко ходить не нужно.
Когда-то давно, Стив Джобс и Стив Возняк создали первый массовый персональный компьютер для массового рынка и поняли, что продавать нужно не компьютеры, а настроение. У Джобса было просто маниакальное отношение к самым мелким деталям, особенно тем деталям, которые касались взаимодействия его продуктов с пользователем - графический интерфейс, материалы компонентов, сценарий взаимодействия с пользователем. Со временем это привело к тому, что люди поверили в его идею и начали также пристально следить за мелочами, что и привело к огромному скачку качества продукции Apple.
Ценовая политика Apple всегда была агрессивной. Они продавали продукт с шокирующим уровнем качества за очень большие деньги. И эта разница в стоимости была заметна сразу.
Традиционно, продукция Apple не была востребована в России из-за высокой стоимости. Но уже сегодня они занимают 5-е место по продаже ноутбуков в РФ и 2-е место на рынке смартфонов. И это сегодня, когда Джобса уже нет, и внимание к деталям уже совсем не то. Качество - это игра в долгую.
К примеру, мой далеко не самый дешевый ноутбук, с которого я пишу эти строки, время от времени использую для работы и для запуска всяких «тяжелых» программерских задач, при более мощных характеристиках стоит ВДВОЕ дешевле, чем аналог от Apple. И все это благодаря стратегии качества.
В нашей Российско-Советской истории на качество делалась очень большая ставка в свое время, знаю не по наслышке от своих родителей, которые трудились на заводах в Soviet Union и гордились тем, что производили продукцию с лейблом «качество». Очень много внимания уделялось качеству производства на предприятиях.


Мой отец работал на Донском заводе радиодеталей. Это уникальное предприятие, которое занимается производством различной керамической и металлокерамической продукции для электротехнических изделий различного назначения, начиная от бытовой электротехники и электроники, и заканчивая чуть ли не космической промышленностью. И уж поверьте, качество там не на последнем месте.
Кстати говоря, вот так выглядит их текущий сайт.
Да и в наши дни находится много тех, кто пытается строить бизнес таким образом, чтобы продавать свои услуги под глифом качества. Думаю что многим знаком слоган, представленный ниже.

Определение качества
Но люди все же не глупые создания. Если бы мы были глупыми, то не занимали верхнее положение в пищевой цепочке на нашей планете. Именно мозги, умение действовать сообща, объединяться в группы и использовать инструменты дало нам превосходство над другими видами и позволило занять главенствующее положение в биосфере.
Вот люди и думают все время, как это качество измерять. И тут каждый во что горазд.
Если речь идет об измерении качества какой-то детали на заводе, то вводится понятие брака. Бракованная продукция - это такая продукция, которая не соответствует каким-то критериям, предъявляемым к этой детали - размерам, шероховатостям, материалам, etc. Проще говоря, если нельзя использовать деталь по ее прямому назначению, то это брак, а человек, который эту деталь сделал - редиска.
Если речь идет о каких-то более массовых, потребительских товарах, то тут уже сложнее. Товаров одного и того же вида много, но поскольку все они существуют на рынке, то нельзя однозначно сказать, что является самым качественным, а что - нет. Например, с той же колбасой. Даже если вы найдете и купите самую дорогую и качественную (по мнению экспертов) колбасу в мире, вы вряд ли ее оцените по тем критериям, по которым привыкли это делать. Также важную роль будут играть ваши персональные вкусовые привычки, которые формировались на протяжении всей жизни, и для вас лично вкусной будет казаться, например, сырокопченая салями, а кому-то больше по вкусу будет обычный сервелат.
Последний пример специально затрагивает больше аспекты предпочтений, нежели качества, потому что при оценке качества каждый потребитель учитывает собственные предпочтения и вкусы. Даже сравнивая два абсолютно одинаковых продукта одного и того же производителя, можно говорить и о предпочтениях, и о качестве, не только как о разных величинах, но и как об одной и той же. Сравнивая две абсолютно одинаковые палки колбасы «на вкус» вы вероятно сможете отличить качественный (не просроченный, не бракованный, а может быть даже и не соотвествующий рецептуре) продукт. Но измерить, насколько один продукт «вкуснее», или «качественнее», вряд ли сможете.
А может быть нам вообще не надо измерять качество? Зачем нам знать, на сколько у.е. один продукт является более качественным, чем другой? Эти вопросы лучше оставить специалистам, которые более предметно изучают эти вопросы и пишут ГОСТ’ы, ISO.
В каждой сфере с качеством есть свои «заморочки». Вот и в разработке программного обеспечения тоже все не очень просто. На прошлом митапе Сергей Москвин уже затронул тему качества программного обеспечения и раскрыл ее со многих сторон. Мы же сегодня попробуем немного сузить круг обсуждения и углубиться в тему обеспечения качества именно программного кода. Делать это будем на примере мной горячо любимого языка PHP.
Определение качества программного кода
Мы живем в очень быстро развивающемся мире. Наша сфера очень молода. При этом она невероятно востребована. Квалифицированных специалистов в мире катастрофически не хватает.
Некоторые страны пытаются бороться с кадровым голодом на государственном уровне. Например, Узбекистан 21 ноября дал старт программе One Million Uzbek Coders. На слух воспринимается довольно непривычно, все же выходцы из Узбекистана у нас в стране ассоциируются не с IT сферой. Но в действительности это очень серьезная мера по развитию IT отрасли в стране, которой в нашей стране не хватает. Главное только чтобы думали не только о количестве, но и о качестве.
Так вот, качество программного кода - это очень сложно измеримая величина. Но как я говорил выше, может быть не стоит заморачиваться насчет измерения, а просто определить критерии, по которым можно понять, что продукт качественный, или нет?
Вопрос качества программного кода можно рассмотреть с двух сторон - со стороны производства и со стороны потребления. Производителем кода является кто? Разработчик. Потребителем кода является кто? Заказчик. Вот каждый и должен принимать решения о том, что для него является качественным, а что нет. Однако в реальности качественным является тот код, который удовлетворяет и тем, и другим.
Если судить с позиции заказчика, то все кажется очень просто. Заказчик хочет, чтобы продукт в целом (а значит и его программный код) удовлетворял некоторым критериям:
- Соответствие тем представлениям, которые есть у него в голове (а значит ТЗ не будет, либо в ТЗ будет написано, что нужно сделать клон ebay)
- Соответствие тому бюджету, который он заложил в продукт (20к достаточно?)
- Соответствие тому сроку, в который он планировал проект получить (Миша, надо вчера уже!)
Более грамотный заказчик думает наперед, и для него помимо этих факторов будут играть роль и другие:
- Расширяемость. Чтобы завтра при появлении новой хотелки он имел техническую возможность ее прикрутить
- Поддерживаемость. Чтобы сопровождение платформы не вызывало проблем
- Надежность. Чтобы продукт работал без сбоев
Еще более грамотные заказчики включают и другие аспекты и требования к тому, чтобы считать продукт качественным.
О чем это говорит? О том, что нет единого мнения на этот счет. Есть попытки формализовать все это и привести к одному конкретному виду, но все равно нет ни одной модели, которая бы позволила с позиции заказчика определить уровень качества и сравнить этот уровень качества с другим продуктом. А в области разработки ПО это вообще не выполнимо, т.к. не существует двух одинаковых продуктов.
Можно рассмотреть вопрос качества еще и с точки зрения разработчика. Тут я буду судить по себе:
- Надежность. (Не сломается ли мой код через 18 лет, когда unix timestamp доберется до предела 32х-битного значения?)
- Эффективность. (Насколько оптимально код использует те ресурсы, с которыми он работает?)
- Юзабельность. (Насколько потребителю, т.е. другому программисту удобно работать с кодом?)
- Реюзабельность. (Могу ли я взять этот кусок кода и переиспользовать его в другом проекте?)
- Тестируемость. (Могу ли я вообще проверить, что мой код работает так, как я ожидаю, желательно без ручных манипуляций?)
- Общая понятность. (Может ли мой коллега джуниор въехать в мой код?)
- Модифицируемость. (Смогу ли я безболезненно встроить новую фичу в мой код?)
- Переносимость. (Смогу ли я перенести свой код на другую площадку/платформу, если вдруг текущая платформа откажет?)
И этот список можно продолжать. У каждого разработчика с опытом он будет разный. Каждый разработчик оценивает качество своего кода и кода окружающих через призму своего собственного опыта.
Если мы будем рассматривать подробно каждый из этих пунктов, то наш митап очень сильно затянется. Поэтому я попробую сконцентрироваться на чем-то более приземленном и наиболее близком к нашим реалиям. Я сейчас говорю об ошибках. Каждая команда является маленьким заводом по производству кода. И задача команды - приносить больше Value наименьшими трудозатратами, в том числе разрабатывая достаточное количество кода с низким процентом брака.
По большому счету для нас, как для программистов, важно писать код таким образом, чтобы в нем было как можно меньше брака, т.е. ошибок. Ошибки бывают разного рода: опечатки, ошибки в синтаксисе, ошибки в стиле оформления, ошибки в типизации, логические ошибки и много-много других. По большому счету можно вывести выражение «Качество == отсутствие дефектов», и оно будет истинно почти всегда.
Мотивация
Зачем я вообще пришел сюда? Кто я такой, чтобы тут размышлять про качество кода?
Я хочу вам признаться. Я - быдлокодер. Был им всю свою карьеру и похоже пока продолжаю им быть. За свои скромные 9 лет опыта в веб-разработке я так и не научился выстраивать системы, которые бы меня устраивали.
Мы сейчас не будем углубляться в причины, из-за которых так получилось, думаю это мало кому интересно. Но одно я знаю точно - так продолжаться не должно.
Я не сегодня открыл для себя эту истину. Я открыл ее для себя уже некоторое время назад. И понимая, что нельзя оставаться на месте, я начал в интернетах по крупицам собирать информацию. Информацию о том, как мне исправить свое текущее положение. О том, как помочь сделать это окружающим. Чтобы мы все вместе пришли к успеху и стали зарабатывать много денег при меньшем количестве усилий, а количество заработанных денег - это отличное мерило того, насколько правильно мы занимаемся какой-то деятельностью.
Я хочу помочь, в первую очередь себе, разобраться в вопросах обеспечения качества своего кода.
Я хочу помочь своим коллегам, чтобы они помогали мне, помогали друг другу в решении вопросов качества.
Я хочу помочь другим, кто возможно занимается поиском ответов на те же вопросы.
Я хочу помочь новичкам, которые сейчас даже пока и не задумываются об этих вопросах, чтобы они в будущем не шли по тем же граблям, что и я.
Я хочу помочь даже своим конкурентам. Когда они не справляются со своими задачами, заказчик может прийти ко мне доделывать этот проект, и я не хочу погружаться в пучину хаоса и безысходности, ковыряя код таких же быдлокодеров, как я.
Стоимость исправления ошибок
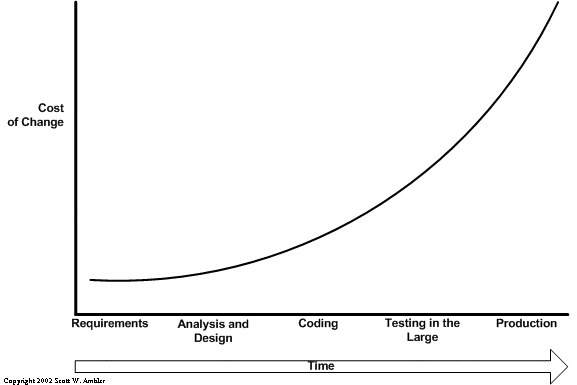
Общеизвестный факт. Между скоростью исправления ошибок и стоимостью этой операции есть экспоненциальная зависимость. Если вы исправите ошибку на этапе сбора требований, то исправление этой ошибки обойдется вам очень дешево. Если же ошибка доберется до продуктива и вы будете править ее там, то стоимость исправления этой ошибки будет в разы выше. Исправление ошибки может не вписаться в архитектуру. Наличие ошибки может оказать влияние на репутацию.
Недавно был случай. Когда-то давно в бородатом 2012м мы делали интеграцию с сервисом, предоставлявшим аккаунты пользователей через OAuth. Не сказать, чтобы сервис был идеально написан, там был «почти» честный OAuth, и работал он стабильно. К нему прилагалась документация со всеми сценариями, которые он поддерживает. И даже «мини-фреймворк», который упрощал интеграцию с системой. Задача сервиса была в том, чтобы хранить аккаунты всех пользователей и предоставлять функции регистрации, аутентификации, управления данными аккаунтов и SSO.
Проект был срочный. Мы подумали как упростить и сделали интеграцию за неделю силами одного разработчика. Проверили все основные моменты - на вид было все ок.
Запуск проекта гладко не прошел. Нам пришлось потратить еще примерно неделю суммарно на стабилизацию всего того, что мы наваяли.
Со временем начали «всплывать» такие сценарии, о которых мы даже и не представляли. Которых не было в документации. У нас начали дублироваться пользователи в локальной СУБД, пришлось думать об их дедупликации. В сторонней системе начали появляться пользователи без данных, которые являются обязательными в нашей системе, пришлось городить «фейковые» данные. Потом вообще стали появляться юзеры, у которых не было ничего, кроме идентификатора. Потом еще, и еще.
Проект жив до сих пор. Отлично чувствует себя и регулярно развивается. Но вот последствия этого всего мы ощущаем до сих пор. На прошлой неделе занимались проблемой, которая приводила к излишне большому количеству редиректов в сценариях аутентификации и регистрации. Суммарно за несколько лет на исправление проблем ушло около двух месяцев чистого времени при изначальных оцененных трудозатратах в неделю. Многие из тех проблем, которые нам пришлось решать, можно и нужно было исправить на самых начальных этапах, но из-за спешки при запуске и отсутствия должного процесса (а иногда и возможности) контроля качества, в итоге имеем то, что имеем.
Если опираться на график, то нам нужно одно из двух:
- либо уменьшать жизненный цикл разработки фичи от начала работы до доставки на продуктив. В этом случае мы получаем быстрый фидбек и можем быстрее вносить изменения
- либо править дефекты настолько рано, насколько возможно, отлавливая их в зародыше
В идеале вообще делать и то, и другое.
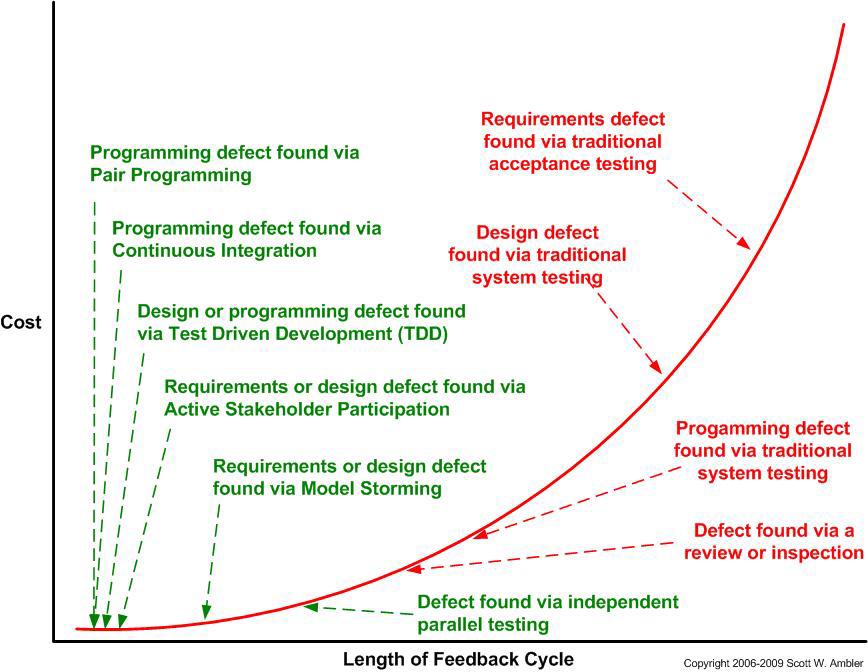
На этом графике можно видеть стоимость исправления ошибки в зависимости от скорости фидбека. Совершенно очевидно, что чем раньше мы получаем обратную связь об ошибке, тем дешевле нам обойдется исправление этой ошибки. Дефекты, найденные в процессе разработки могут быть исправлены почти бесплатно. С другой стороны, исправление дефектов, найденных с помощью ревью, уже будет стоит гораздо дороже.
В скорости обнаружения дефектов должны быть заинтересованы все, и в первую очередь бизнес, потому что он за все платит. Даже если вы исправляете ошибки в режиме гарантии, это не значит, что бизнесу должно быть все равно. Он все равно несет потери - временнЫе, репутационные. Один небольшой дефект, который прожил в продукте несколько лет, может привести к очень сильному эффекту бабочки, и если бизнес не заинтересован в том, чтобы этого эффекта избежать - надо что-то с этим делать.
Во вторую очередь это должно быть интересно самим разработчикам. Никто не хочет падать в грязь лицом и выкатывать продукт с дефектами намеренно. Конечно, мы не идеальны, невозможно гарантировать стопроцентное отсутствие ошибок. Мы часто работаем в условиях ограниченной информации, либо ее отсутствия. Мы люди и мы тоже имеем право на ошибку. Но мы должны делать все возможное, чтобы минимизировать их количество.
Ну и потом скорость нахождения ошибки должна волновать всех остальных - менеджерский аппарат, пользователей продукта. Да даже вашу уборщицу! Вдруг у вас случится нервный припадок от того, что вы нашли какую-то адскую багу на проде, которая в ближайшие дни будет сосать вашу кровь и вы бросите свою кружку в стену, или не дай бог соседа? В прочем, это конечно вряд ли 🙂 (я надеюсь)
Про QA

Разработчики любят полагаться на тестеров. А тестеры любят воевать с разработчиками. Но QA - это не вотчина тестировщиков, как многие почему-то думают. На прошлом митапе мы уже обсуждали, что QA - это огромная область, которая включает в себя множество аспектов контроля качества программного обеспечения.
Я считаю, что каждое заинтересованное лицо в проекте так или иначе должно принимать участие в процессе контроля качества, но со своей колокольни. Продакт должен продумать фичу таким образом, чтобы она отвечала требованиям бизнеса. Аналитик должен качественно проработать требования, чтобы они не содержали противоречий и были понятны. Юзабилист с дизайнером должны построить удобный и красивый интерфейс, не вызывающий затруднений у пользователей. Разработчики должны реализовать фичу так, чтобы она вела себя так, как было задумано бизнесом и не сбоила. Техписы должны написать качественную документацию, которая позволит быстро погрузиться в задачу через длительное время, а также позволит пользователям найти все ответы самостоятельно и быстро.
Наибольшую степень контроля над качеством продукта по моему мнению должен брать на себя разработчик, потому что именно на этапе разработки наиболее выгодно его контролировать.
Вот на этом мы и сосредоточимся сегодня.
Чистый код
Что такое чистый код? Я как-то смотрел одно из видео Дядюшки Боба (Роберта Мартина), где он рассказывал, как задал одному из своих коллег этот же вопрос. Ответ поразил его. Коллега ответил ему, что чистый код - это когда ты открываешь функцию, смотришь на ее код и видишь там именно то, что ты ожидаешь.
Обычно же как? Ты смотришь в код, видишь там обращение к какой-нибудь функции:
$comparsionResult = CompareDates($dateFrom, $dateTo);
Заходишь внутрь, чтобы посмотреть, а там какая-нибудь дичь:
// 1 if date1 > date2
// 0 if date1 = date2
// -1 if date1 < date2
function CompareDates($date1, $date2)
{
$s_date1 = $this->CharToDateFunction($date1);
$s_date2 = $this->CharToDateFunction($date2);
$strSql = "
SELECT
if($s_date1 > $s_date2, 1,
if ($s_date1 < $s_date2, -1,
if ($s_date1 = $s_date2, 0, 'x')
)) as RES
";
$z = $this->Query($strSql, false, "FILE: ".__FILE__."<br> LINE: ".__LINE__);
$zr = $z->Fetch();
return $zr["RES"];
}
И ты такой - WTF??? Ну ок, может быть даже исправляешь это. Идешь дальше. Видишь обращение к функции make_json. Отладчик привел тебя туда. Ты заходишь и видишь:
function make_json($array){
$json = '{';
$pairs = array();
foreach($array as $key=>$val){
if (!is_numeric($val)) { $val = "'{$val}'"; }
$pairs[] = "{$key}: $val";
}
$json .= implode(', ', $pairs);
$json .= '}';
return $json;
}
И опять - WTFF??
Так вот Роберт Мартин вывел самое лучшее определение для чистого кода ever.

Но мне кажется, что мы живем в совсем другом мире. Возможно дело в языке?
Но давайте все же «поближе к телу».
Опыт поколений
Мы все с вами далеко не самые первые программисты во вселенной. До нас была уже пара поколений программистов, и они не сидели сложа ручки, они оставили нам свое наследие, которым ну просто грех не воспользоваться.
Начнем с самого простого и понятного всем, быстренько пройдемся, а дальше будем двигать по нарастающей.
Стилистика. Naming
There are only two hard things in Computer Science: cache invalidation and naming things.
- Phil Karlton
Прочитал я когда-то в блоге Мартина Фаулера.
Делайте имена переменных, функций, классов, методов, констант понятными. Вы пишете программу не для кого-то. Вы пишете программу для людей, которые потом будут эту программу читать. Компилятору/интерпретатору все равно. Но вот людям - нет. Вы же сами через полгода вернетесь к этому коду и вы сами же будете вспоминать, что вы имели в виду, когда давали переменной такое имя и возненавидите себя.
Основные моменты, на которые нужно обращать внимание:
- никаких однобуквенников. Максимум - это для обозначения какого-то очень локального значения типа счетчика в цикле (но можно и без него обойтись)
- никакой транслитерации
- не стоит перегибать палку и делать чересчур понятные имена из 40 символов
- осторожнее с сокращениями
- использовать единую нотацию (но не венгерскую)
- в названии должен быть смысл и семантика
// Однобуквенники - не надо. Только в "классических" случаях, понятным всем, например $i++
// $a;
// $b;
// Транслитерация - не надо
// $nachalo;
// $konets;
// Слишком длинные и избыточные имена - не надо
// $beginningOfCalculationCycle
// $endingOfThatSloppyWork
// Непонятные и бессмысленные сокращения - не надо
// $lst
// $lend
// Венгерская нотация - не надо
// $iLoopStart
// $iLoopEnd
// Больше смысла и семантики
$loopStart = 0;
$loopEnd = 10;
$loopIterator = new LoopIterator($loopStart, $loopEnd);
echo $loopIterator->iterateOver(2);
Пара примеров из жизни:
function InitBVarFromArr($arr)
{
if (is_array($arr) && count($arr)>0)
{
foreach($arr as $value)
{
global $$value;
$$value = ($$value=="Y") ? "Y" : "N";
}
}
}
Что хотел этим сказать автор - не понятно. Это пример кода из моей горячо «любимой» CMS, не будем произносить это слово вслух.
Старайтесь давать вашим сущностям (переменным, функциям, классам, интерфейсам, константам и т.д.) достаточно понятные, но при этом не длинные и лаконичные имена. Основной посыл в том, чтобы вы думали о человеке, который через полгода будет читать этот код (им вполне можете оказаться вы сами). Если вы подумаете об этом - много времени это не отнимет, но в будущем может сэкономить и чьи то нервы, и чьё то время.
Пара слов о венгерской нотации. Это касается любителей Битрикса особенно. Ну не актуальна она уже. Если вы что-то слышали о ней - непременно забудьте. Если вы пользуетесь венгерской нотацией в современном php, то вы тратите человекочасы напролет чтобы набирать все эти str, ar, int, db и прочие префиксы. При всем при том эти самые префиксы очень часто не соответствуют действительному значению в этих переменных. Зачем тогда обманывать себя и других?
В php уже давно подвезли статическую типизацию и ее хватает для большинства базовых кейсов. Чуть позже расскажу об этом подробнее.
Стилистика. Поведение
Oneliner
Oneliner’ы - древнее зло. Я терпеть не могу oneliner’ы и очень не рекомендую ими злоупотреблять
foreach(explode(' ',str_replace($symbols,'',htmlspecialchars_decode(html_entity_decode(implode(' ',$keywords))))) as $i=>$val) if(mb_strlen($val)>2) echo ', '.$val;
Как вообще можно нормально разобрать, что тут происходит? Это же настолько сильная головная боль. Не надо делать так. Разбейте вы на несколько операций это дело.
foreach ($keywordsList as &$keyword) {
$keyword = html_entity_decode($keyword);
$keyword = htmlspecialchars_decode($keyword);
$keyword = str_replace($symbols, '', $keyword);
}
echo implode(', ', $keywordsLlist);
Примерно такую же головную боль доставляют вызовы, многократно вложенные друг в друга.
$arCallbacks = implode(
'. ',
array_filter(
array_map(
'trim',
explode(
'+',
$arSettings['getSourceCallback']
)
),
'is_callable'
)
);
Это ведь по сути точно такой же oneliner, только разбитый на несколько строк. Если вас прижало писать в подобном стиле - сделайте fluent интерфейс, благо библиотек сейчас навалом.
$arCallbacks = piped($arSettings['getSourceCallback'])
->explode('+')
->trim()
->filter('is_callable')
->implode('. ')
->getValue();
Небольшая история из моего прошлого. Однажды, когда я был совсем молодой и неопытный, выдал ведущий разработчик мне задачку, на которую он сам не смог найти времени. Задача заключалась в том, чтобы исправить поведение небольшого js скрипта, который рендерил стилизованный select.
Я взялся за эту задачу, полез копаться в код. Первое, что мне не понравилось, это что автор библиотеки дал не очень емкие названия переменным (a, b, c, y, x). Некоторые переменные состояли из двух, трех букв, но логики в их именовании я не нашел. Форматирования там тоже не было никакого.
Спустя пару дней я откопал ошибку, смог кое как с помощью alert’ов отладить работу скрипта и исправить его поведение, чем был очень горд, считал себя очень крутым чуваком потом. Пошел сдавать ведущему, тот проверил работу, очень удивился, что я в этом всем разобрался. Похвалил и дал другую задачку.
Все бы ничего, но знаете как выглядел тот код?

Это я только потом уже узнал, что это был минифицированный js … Наверно с тех пор я больше и не люблю oneliner’ы.
Условия и вложенность
Я очень люблю условный оператор. Он очень простой. Это одна из самых первых и самых понятных концепций в императивном программировании. И так больно видеть каждый раз, когда все эти условия дико переусложняют.
Тут есть несколько важных, но очень простых правил:
- использовать правило раннего возврата из функции
- избегать использования else
- не использовать elseif и тем более else if
- помните, что еще есть case
- тело условия надо максимально упрощать
Знайте. Если вы где-то написали else, или elseif - то скорее всего можно обойтись и без них. Есть мнения, что можно вообще обойтись даже без if. Если у кого-то был опыт - дайте знать, интересно.
Ранний возврат вообще - очень крутая и удобная практика. Она позволяет отметать все лишнее. Благодаря этому сразу уменьшается и вложенность кода, и количество абстракций, которые нужно держать в голове, сводится к минимуму лишняя работа, само количество кода уменьшается (хотя кажется, что наоборот).
Более подробно - https://habr.com/ru/post/348074/.
И не надо усложнять тело условия. Чем меньше операндов там будет, тем проще можно будет их понять.
Вложенность
Не могу не вставить эту классическую картинку

Боритесь со вложенностью как можете. Это один из злейших врагов, который не даст вам быстро и просто разобраться в хитросплетениях логики.
foo {
bar {
baz {
quz {
quux {
corge {
grault {
garply {
// waldo
}
}
}
}
}
}
}
}
https://twitter.com/RichardWestenra/status/765488378951376896
Увидел случайно у одного британского разработчика в twitter. Он предлагает бороться со вложенностью кода, добавляя к каждому уровню вложенности столько пробелов, сколько их в последовательности Фибоначчи. Мне кажется это очень крутой способ, ждем когда подвезут в IDE.
Отличным способом борьбы со вложенностью является как раз ранний возврат из функции. Да, это немного увеличит количество строк в вашем коде, но оно того стоит.
Ниже пример кода с одного из проектов, который я писал около семи лет назад.
public static function storeGoogleClientId() {
if (!isset($_SESSION['GOOGLE_CLIENT_ID']) && isset($_COOKIE['_ga'])) {
$gaCookie = explode('.', $_COOKIE['_ga']);
if (isset($gaCookie[2])) {
$clientId = $_COOKIE['_ga'];
if (preg_match('#^[0-9A-F]{8}-[0-9A-F]{4}-4[0-9A-F]{3}-[89AB][0-9A-F]{3}-[0-9A-F]{12}$#i', $gaCookie[2])) {
$clientId = $gaCookie[2];
} elseif (isset($gaCookie[2]) && isset($gaCookie[3])) {
$clientId = $gaCookie[2] . '.' . $gaCookie[3];
}
}
$_SESSION['GOOGLE_CLIENT_ID'] = $clientId;
} elseif (!isset($_SESSION['GOOGLE_CLIENT_ID'])) {
$clientId = $_COOKIE['uuid'];
if (!$clientId) {
$clientId = generateUUID();
setcookie('uuid', $clientId, 60 * 60 * 24 * 12 * 2);
}
$_SESSION['GOOGLE_CLIENT_ID'] = $clientId;
}
}
Это очень старый код. Гордиться тут нечем. Не надо писать такой код в 2020 году. Но я уверен, что у каждого был когда-то период, когда он писал нечто подобное.
На его примере постараюсь показать некоторые приемы его упрощения и улучшения.
function getUuid(string $googleClientId)
{
$googleClientIdParts = explode('.', $googleClientId);
$uuid = $googleClientIdParts[2] ?? '';
if (!$uuid) {
return $uuid;
}
return $uuid;
}
function getLocalUuid()
{
return $_SESSION['GOOGLE_CLIENT_ID'] ?? '';
}
function validateUuid(string $uuid)
{
$regexp = '/^[0-9A-F]{8}-[0-9A-F]{4}-4[0-9A-F]{3}-[89AB][0-9A-F]{3}-[0-9A-F]{12}$/i';
return preg_match($regexp, $uuid);
}
function storeClientId(string $clientId)
{
setcookie('uuid', $clientId, 60 * 60 * 24 * 12 * 2);
}
function storeLocalClientId(string $clientId)
{
$_SESSION['GOOGLE_CLIENT_ID'] = $clientId;
}
function storeGoogleClientId()
{
$localClientId = getLocalUuid();
if ($localClientId) {
return;
}
$clientId = $_COOKIE['_ga'] ?? '';
$alternativeClientId = $_COOKIE['uuid'] ?? '';
if (!$clientId && !$alternativeClientId) {
$uuid = generateUUID();
storeClientId($uuid);
storeLocalClientId($uuid);
return;
}
if (!$clientId) {
return;
}
$gaCookie = explode('.', $clientId);
$uuid = $gaCookie[2] ?? '';
$userId = $gaCookie[3] ?? '';
if (!$uuid) {
storeLocalClientId($clientId);
return;
}
if (validateUuid($uuid)) {
storeLocalClientId($uuid);
return;
}
if ($uuid && $userId) {
storeLocalClientId($uuid . ' ' . $userId);
}
}
Бесспорно, кода стало больше. Но он стал более удобным для чтения и реиспользования.
Строгая типизация
interface OrdersRepositoryInterface
{
/**
* @param int $infotechOrderId
* @return Order|null
*/
public function getByInfotechId(int $infotechOrderId): ?Order;
/**
* @param int $bitrixOrderId
* @return Order|null
*/
public function getByBitrixId(int $bitrixOrderId): ?Order;
public function persist(Order $order);
}
Каждый должен для себя решить, насколько строгим должен быть код. Php дает огромные по приведению типов, но при этом он дает миллион способов выстрелить себе в ногу. Я сторонник более строгого подхода к написанию кода, и чем больше обложиться типами, тем меньше вероятность столкнуться с ошибкой приведения типов.
<?php declare(strict_types=1);
К великому сожалению не многие еще знают про declare и про более строгий режим работы с типами в php. Используйте на здоровье
Исключения
К сожалению крайне редко вижу, чтобы php разработчики использовали исключения, а зря. PHP разработчики часто относятся к исключениям как к неудобному способу обработки ошибки. Часто проще вернуть false в случае ошибки или какой-нибудь null.
class CartItem
{
// ...
public function changePrice(int $price)
{
if ($price < 0) {
return false;
}
$this->price = $price;
return true;
}
}
В мире битрикса распространен механизм возвращения специального объекта, который содержит информацию о результате работы какой-то процедуры с возможностью проверить его на ошибку.
class CartItem
{
// ...
public function changePrice(int $price): Result
{
$result = new Result();
if ($price < 0) {
$result->addError(new Error('Стоимость не может быть отрицательной'));
$result->setData(['PRICE' => $price]);
return $result;
}
$result = $this->setPrice($price);
if (!$result->isSuccess()) {
return $result;
}
return $result;
}
}
Да, действительно, исключения уместны не всегда в бизнес-логике. Я предпочитаю размышлять об исключениях как о способе прервать исполнение какого-то кода с возможностью выбросить ошибку на любой вышестоящий уровень по стеку вызова.
Прервать - значит прервать. Если исполнение кода невозможно продолжить далее из-за какой-то ошибки - то можно бросать исключение. Оно позволит вам выбросить на уровень выше все то, что необходимо для обработки ошибки. На нужном уровне достаточно будет поймать это исключение с помощью нативных возможностей языка. Как по мне - довольно удобный способ.
class CartItem
{
// ...
/**
* @param int $price
* @throws SomeException
*/
public function changePrice(int $price)
{
if ($price < 0) {
throw new SomeException('Стоимость не может быть отрицательной', $price);
}
}
}
Избегайте глобального и статического контекста
Скорее всего ни для кого тут не секрет, что глобальный контекст - это плохо. Но возможно не все понимают, что глобальный контекст - гораздо более широкое понятие, чем возможно вы думали.
Ключевое слово global и суперглобальный массив $GLOBALS - это маркеры, которые позволяют понять, что в коде что-то идет не так. Но ведь помимо них есть еще всякие $_SESSION, $_REQUEST, $_GET, $_POST, $_FILES, $_COOKIES и прочие.
А как насчет статического контекста? Если вы написали статический метод у класса, то это уже по сути глобальная функция, которая может быть вызвана из любой части программы. А если внутри такого статического класса записываются статические переменные, использующиеся в других местах, то вы обязательно когда-нибудь потеряете контроль над их состоянием.
То же самое касается синглтона. Синглтон - хороший паттерн. Но часто он снабжается каким-нибудь статическим методом getInstance, который позволяет получить единственный экземпляр этого класса, который по-моему и является основным источником проблемы. Хотите один единственный экземпляр класса на приложение - положите его в Dependency Injection Container или в Repository. Но об этом чуть позже.
В общем - бойтесь глобальных штук, которые можно поменять из любого места программы.
Неявное и не очевидное поведение
Старайтесь писать код таким образом, чтобы не приходилось долго думать над тем, что именно он делает. Это кажется простым, но одновременно оно является очень сложным.
Более того, не надо писать код, который будет делать что-то за спиной разработчика, или будет использовать какие-то конструкции, которые не являются очень «редкими» в кругах тех разработчиков, которые занимаются поддержкой кода
Вот небольшой список того, чего стоит избегать:
- eval
- $$variable
- extract
- compact
- FLAG1 | FLAG2 & FLAG3 ^ FLAG4
- goto
«Чистые» функции
Нужно стремиться к чистоте функций. Функция является чистой только при соблюдении двух условий:
- функция при одинаковых входных данных будет возвращать всегда одинаковый результат (детерминированность)
- функция не должна иметь побочных эффектов
Совершенно очевидно, что нельзя сделать любую функцию чистой. Например, функция rand() не может быть детерминированной по определению. То же самое касается итераторов/генераторов. Иногда без них нельзя обойтись. Но в очень большом количестве случаев можно будет сделать функцию детерминированной.
Что касается побочных эффектов - просто не возлагайте на функцию какой-то дополнительной работы тогда, когда это возможно. Невозможно сделать весь код без побочных эффектов, но будет гораздо лучше, если его количество будет меньше, чем количество чистых функций.
function dump($data)
{
return "<pre>" . print_r($data, true) . "</pre>";
}
Вот пример чистой функции. На вход она принимает один аргумент. На выход возвращает форматированную строку. Сама функция не производит никаких побочных эффектов, и результат всегда будет зависеть от входящего аргумента.
global $debugHistory;
function dump($data)
{
$debugHistory[] = $data;
return "<pre>" . print_r($data, true) . "</pre>";
}
Так же функция, но уже с побочным эффектом, который будет записывать историю работы функции в глобальное состояние. Нужно избегать таких вещей.
function dump($data)
{
ob_start();
echo "<pre>" . print_r($data, true) . "</pre>";
$dump = ob_get_clean();
echo date('Y-m-d H:i:s') . ' ' . $dump;
return $dump;
}
Ну и еще раз та же самая функция, только теперь она и производит побочный эффект (вывод в stdout) и результат ее зависит от внешних факторов (дата). Такого тоже нужно избегать.
Немного ближе к телу и чуть более реальные примеры.
class ImageResizer
{
protected $engine;
protected $defaultWidth = 100;
protected $defaultHeight = 100;
public function __construct(ResizerEngineInterface $engine)
{
$this->engine = $engine;
}
public function resize(string $imagePath, ImageParamsInterface $imageParams)
{
$width = $imageParams->getWidth() ?? $this->defaultWidth;
$height = $imageParams->getHeight() ?? $this->defaultHeight;
return $this->engine->resize($imagePath, $width, $height);
}
}
Здесь представлен простой класс, который выполняет изменение размера изображения с помощью внешнего «движка». Данный класс не производит никаких сайд эффектов сам по себе. Его единственный публичный метод resize всегда будет возвращать один и тот же результат в зависимости от входных параметров.
class ImageResizer
{
protected $engine;
protected $logger;
protected $defaultWidth = 100;
protected $defaultHeight = 100;
public function __construct(ResizerEngineInterface $engine, \Psr\Log\LoggerInterface $logger)
{
$this->engine = $engine;
$this->logger = $logger;
}
public function resize(string $imagePath, ImageParamsInterface $imageParams)
{
$width = $imageParams->getWidth() ?? $this->defaultWidth;
$height = $imageParams->getHeight() ?? $this->defaultHeight;
$resizedImage = $this->engine->resize($imagePath, $width, $height);
$this->logger->debug(
'Resized an image {src} to {width}x{height} down to size {size}',
[
'src' => $resizedImage->getSrc(),
'width' => $resizedImage->getWidth(),
'height' => $resizedImage->getHeight(),
'size' => $resizedImage->getSize()->humanize(),
]
);
return $imageParams;
}
}
Тот же самый код - но уже с внедренным в него логгером. Побочный эффект, который он производит - это запись в лог.
Ничего страшного в этом примере нет, если вы держите все побочные эффекты под контролем. Но лучше стараться избавлять свой код от них по максимуму. Не всегда можно избавиться от них, но нужно стараться.
Сеттеры - почти антипаттерн
Не надо в своих классах давать возможность мутировать состояние с помощью сеттеров. Но тут стоит уточнить, что имеется в виду под сеттерами.
$product = new Product();
$product->setWeight(1500.00);
$product->setPrice(2000);
Я вот про те сеттеры, которые указаны выше в примере.
Под сеттером в данном случае я имею в виду способ установить значение для какого-то поля класса, которое недоступно извне. Сеттеры обычно используют для целей инкапуслирования, чтобы сокрыть от внешнего мира способ установки значения поля. Например, можно валидацию прикрутить на сеттер.
Я видел разные примеры использования сеттеров. Кто-то использует сеттеры как замену конструктору, и при этом не задумывается о том, что на самом деле таким образом делает класс с кучей необязательных полей. Кто-то использует сеттеры для изменения состояния объекта с помощью какой-то внешней бизнес-логики. Кто-то использует сеттеры для внедрения зависимостей.
Каждый раз, когда вы добавляете какое-то поле в класс, значение которого вам нужно менять извне, вы просто добавляете сеттер, думая что это ОК.
Но в действительности такие сеттеры не нужны. Я не говорю, что вам нужно взять и завтра поудалять все методы ваших классов с префиксом set, конечно же нет. Но вам стоит подумать о поведении вашего кода, о вашей семантике и о бизнес-целях, а также о настоящей инкапсуляции и разделении состояния и поведения.
Во-первых, стоит оперировать состоянием. Ваш класс - это так или иначе какое-то состояние, которым вам нужно управлять. Чтобы создать новый экземпляр с каким-то состоянием, следует использовать конструктор. Замените свои сеттеры на конструкторы. Вот так выглядит предыдущий код в IDE с замененными на конструктор сеттерами:
class Product
{
protected $price;
protected $weight;
public function _construct(int $price, float $weight)
{
$this->price = $price;
$this->weight = $weight;
}
}
$product = new Product (2000, 1500.00);
IDE даже подсказывает сразу при обращении к конструктору, какие поля вы устанавливаете в состояние своего будущего экземпляра. Удобно же.
Подавляющее количество кода, который мы пишем, так или иначе призвано для решения каких-то бизнесовых задач. Вот и оперируйте бизнесовыми терминами, раз уж оно так. Если вам нужно изменить имя пользователя, то вместо метода setName добавьте метод changeName, это будет ближе к бизнес цели. Если бизнес-логика вашего класса подразумевает изменение стоимости в процессе его существования в одном из бизнес-сценариев, то так и назовите метод - «изменитьСтоимость».
class Product
{
public function changePrice(int $price)
{
// ...
}
}
$product = new Product(2000, 1500.00);
$product->changePrice(3000);
Если вам нужно снять средства со счета, то вместо вызова setAmount создайте метод withdraw. Ну и далее в таком же стиле
final class Billing
{
protected $balance;
public function __construct(int $balance)
{
$this->balance = $balance;
}
public function withdraw(int $amount)
{
if ($amount <= 0) {
throw new WithdrawException('Сумма списания должна быть положительной');
}
if ($amount > $this->balance) {
throw new WithdrawException('Баланс не может быть отрицательным');
}
$this->balance -= $amount;
return new self($balance);
}
}
$billing = new Billing(100);
$billing = $billing->withdraw(50);
Мутабельность и иммутабельность
Холиварная тема.
Любой объект, созданный как экземпляр любого класса php по природе будет мутабельным, если вы явно разрешили изменение его состояния извне. По правде сказать, в php не существует совсем честных иммутабельных объектов, но оставим это за пределами данного обсуждения. Любой объект - это состояние, которое можно изменить с помощью интерфейса, предоставляемого классом.
Но вы должны помнить, что любой объект в php всегда передается по ссылке (почему-то для многих это становится открытием). Если вы пропихнули объект какого-то класса в какую-то функцию и изменили его там, то эти изменения будут применены везде, где используется именно этот экземпляр. Часто разработчики почему-то забывают об этом и могут случайно стрельнуть себе в ногу.
Можно упороться и клонировать объект перед каждой попыткой передать его куда-то, но часто это не нужно.
Не нужно делать каждый свой класс иммутабельным, вам будет очень сложно с этим работать. Но есть определенный класс задач, где иммутабельность очень удобна. Если объект вашего класса никак не соотносится с какой-то сущностью реального мира (записью в БД, например), а также этот класс является представлением какого-то скалярного значения, или их комплекса, то удобнее будет сделать объект иммутабельным. Даты, строки, числа - все это можно сделать иммутабельным и с этим будет удобнее работать, т.к. вы точно не сможете в них запутаться.
function getReport(DatasourceInterface $datasource, \DateTime $date)
{
$dateFrom = $date->setTime(0, 0, 0);
$dateTo = $date->setTime(23, 59, 59);
$filter = [
'dateFrom' => $dateFrom,
'dateTo' => $dateTo,
];
return $datasource->fetchByFilter($filter);
}
$date = new DateTime('today');
$report = getReport($datasource, $date);
Предположим, что у нас есть функция генерации отчета, которая на вход принимает источник с данными и отчет. Функция формирует фильтр для выполнения запроса, модифицируя входную дату дважды. Если мы выведем содержимое переменной $filter на экран, то увидим следующее:
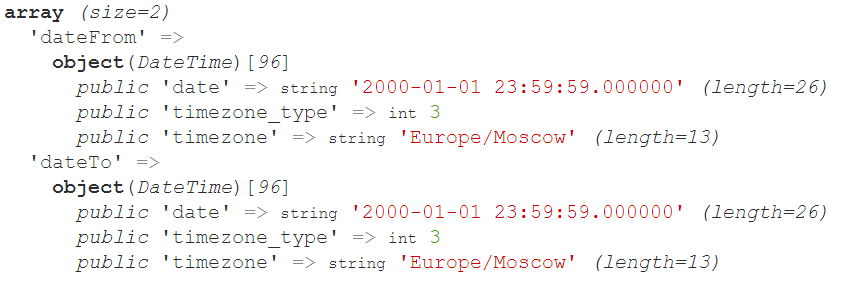
Чтобы такого не произошло, стоит клонировать даты перед их изменением, либо лучше использовать \DateTimeImmutable
function getReport(DatasourceInterface $datasource, \DateTimeImmutable $date)
{
$dateFrom = $date->setTime(0, 0, 0);
$dateTo = $date->setTime(23, 59, 59);
$filter = [
'dateFrom' => $dateFrom,
'dateTo' => $dateTo,
];
return $datasource->fetchByFilter($filter);
}
$date = new DateTimeImmutable('today');
$report = getReport($datasource, $date);
Есть еще много способов стрельнуть себе в ногу. Например, в том же DateTimeImmutable можно вызвать констркутор дважды (да, привет php). Тогда можно будет изменить состояние. Но это тема уже отдельной статьи или доклада.
Помимо наследования есть еще и композиция
Часто бывает, что разработчики выбирают наследование там, где это может быть не обоснованно. Но не единым наследованием можно расширить функционал какого-то класса. Мы можем применить композицию к классу как способ расширения его возможностей.
Вообще, насколько я понял, это очень холиварная тема. Нельзя полностью заменить наследование композицией, и наоборот. Хотя некоторые пытаются. Поэтому тут приходится думать головой каждый раз перед принятием решения.
Корень этой проблемы кроется, как мне кажется, в некорректном трактовании самого наследования. Мы исторически привыкли ассоциировать наследование в программировании с наследованием в реальном мире. Я являюсь наследником своего отца. Человек происходит от обезьяны. Квадрат является наследником от прямоугольника (или наоборот?).
В реальности слово «Наследование» надо было заменить на «Расширение». И как бы слово «extends» прямо намекает об этом.
Если вам нужно «расширить» какой-то существующий класс - вы берете его за основу и докидываете туда дополнительную функциональность. Вы получите всю ту функциональность, которую имеет расширяемый класс плюс все то, что вы туда допишите. При такой схеме будет сложно (да и бессмысленно) удалять какую-то функциональность расширяемых классов.
Другой случай - подумать о типе взаимосвязи между расширяемым и разрабатываемым классами. Если можно сказать, что NewClass IS A BaseClass, то вероятнее всего будет лучше использовать наследование. Если же BaseClass HAS A NewClass, то лучше прибегнуть к композиции.
Ну а если вам нужно что-то из класса удалить, то тут скорее всего будет правильнее воспользоваться именно композицией.
class User
{
protected $email;
protected $name;
public function __construct(string $email, string $name)
{
$this->email = $email;
$this->name = $name;
}
public function getEmail()
{
return $this->email;
}
public function getName()
{
return $this->name;
}
}
class Customer extends User
{
public function __construct(string $name)
{
parent::__construct('', $name);
}
public function getEmail()
{
return null;
}
}
Допустим, у нас есть класс «пользователь» и «клиент», который его расширяет. Клиентом - простой посетитель сайта, о котором мы не знаем ничего, даже email, поэтому мы переопределяем метод getEmail таким образом, чтобы он всегда был null. Но если мы откроем IDE и попытаемся поработать с этим классом, мы увидим возможность обратиться к email, хотя его там по сути никогда нет
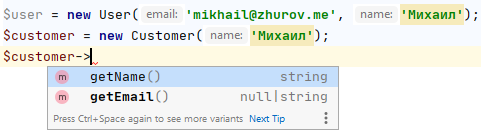
Если же применить композицию вместо наследования - можно исправить это недоразумение
class Customer
{
protected $user;
public function __construct(User $user)
{
$this->user = $user;
}
public function getName()
{
return $this->user->getName();
}
}
Это бесконечный список
- Кешируй
- Инвалидируй кеш по бизнес-логике
- Не доверяй пользовательскому вводу
- Проверяй наличие индекса в ассоциативном массиве
- Логи php смотри
- Не передавай по ссылке где попало
- Не делай запросы в циклах
- Используй автозагрузку
- Используй пакетный менеджер, не пиши велосипеды
- Используй xDebug для отладки
- Фильтруй логи
- …
- Думай головой
Можно очень долго перечислять аспекты написания хорошего кода. Но все они не уместятся ни в одну статью, придется книжку написать. Поэтому мы пока пойдем дальше к другим вещам, которые стоит рассмотреть. Но самое главное - это последний пункт из предыдущего списка - думать головой. Нужно создавать как можно больше барьеров, чтобы не выстрелить себе в ногу. Но любые правила можно нарушать, если на то есть логическое обоснование.
Стилистика. Codestyle
Мы понемногу подходим к стандартам. За все время существования индустрии люди успели написать сотни гигабайт кода. И естественно выработался определенный свод правил, которому рекомендовано следовать для достижения наибольшего профита, доступного на данный момент.
Расстановка переносов строк, длина имен переменных, способ именования, вложенность, расстановка пробелов и знаков препинания - все это Codestyle.
В мире PHP есть определенный свод рекомендаций, которые вырабатывались на протяжении длительного времени у разных передовых компаний. Есть рекомендации от:
А еще есть целая организация PHP-FIG, в которую входит ряд довольно продвинутых разработчиков из уже упомянутых проектов, и они совместно разрабатывают рекомендации по работе с кодом. У них много разных рекомендаций. По части оформления кода у них есть PSR1, PSR2 и не так давно одобренный PSR12.
Эти рекомендации описывают правила, которым нужно следовать при оформлении кода, чтобы вам жилось лучше.
Что самое крутое - вам даже не очень то нужно знать, что там в этих правилах написано. Если вы используете IDE от Jetbrains, то в настройках проекта вы можете легко включить любой из поддерживаемых стандартов прямо в настройках редактора.
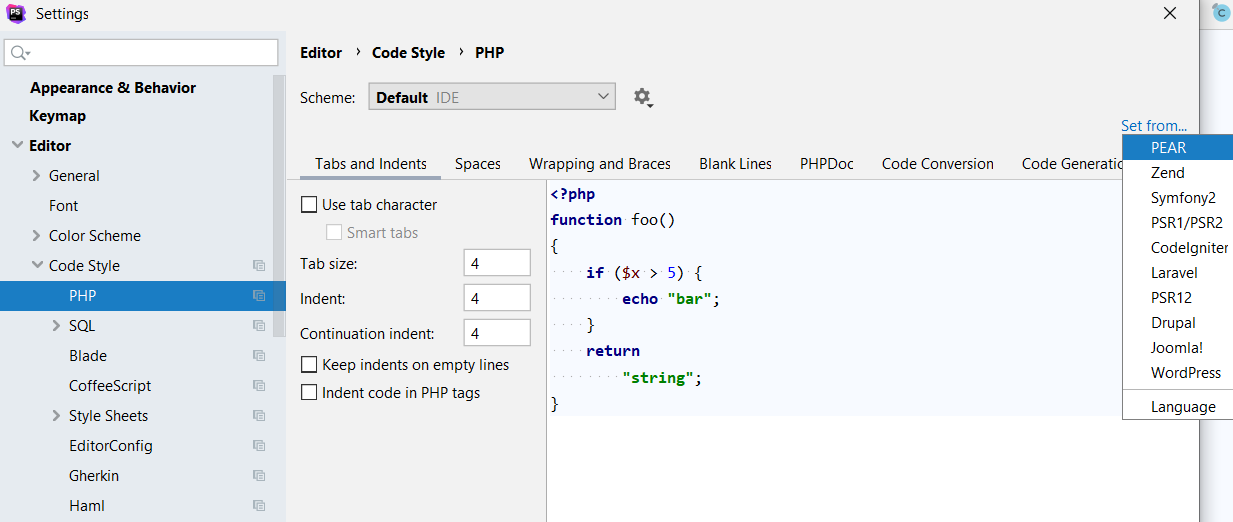
Уверен, что сейчас такая штука есть много где.
Пока вы будете писать новый код, IDE уже будет помогать вам следовать этим стандартам. Всяческие действия с автокомплитом будут автоматически форматировать ваш код по стандартам. У вас появится возможность нажатием всего одного хоткея отформатировать любой даже самый обфусцированный код в соответствии с тем стандартом, который вы выбрали.
А что делать людям, которые не желают использовать неповоротливые IDE? А если нужно проверить сразу весь проект на соответствие Codestyle? А если вообще хочется весь проект сразу же отформатировать на соответствие этим правилам? А запретить отправлять на продуктив какой-то код, который этим правилам не соответствует?
Вот тут нам на помощь приходят инструменты, которые можно запустить без IDE. На сегодняшний момент популярных инструментов несколько:
Достаточно подключить их в проект с помощью composer в качестве dev зависимости, или в качестве глобальной, потом написать небольшой конфигурационный файл и начать запускать их с помощью одной команды.
А вот так выглядит результат работы команды фикса, которая изменяет все файлы, подходящие под настройки, одним махом.
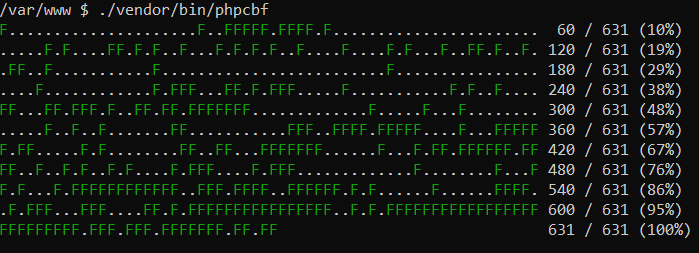
Подумать только. 1290 ошибок в почти 250 файлах
Понятно, что использовать это нужно с умом. Например, не стоит сразу запускать фикс всего кода на проекте, когда в производстве находится несколько фич у других разработчиков этого же проекта - замучаются потом сливать свои правки с вашими, если были общие изменения. Но инструмент, однако, полезный.
Причем тут качество? Это же все фенечки
Очень даже причем. Не оформленный код можно сравнить с бардаком. Допустим, вы хотите снять квартиру и выбираете между двумя почти одинаковыми вариантами. В одной из них будет страшный бардак - грязные заляпанные обои, пыль кругом, треснувшее стекло на балконе, какие-то масляные пятна на полу, запах курева в туалете. Другая будет просто чисто ухоженной без этих недостатков, но меньше по размеру и немного дороже. Что вы выберете? Наверно, зависит от приоритетов. Но мне было бы приятнее жить в чистой ухоженной квартире, это бы лучше сказалось на моем качестве жизни.
В коде примерно то же самое. Вам будет гораздо проще разобраться в том коде, который был хорошо оформлен. Вам придется тратить меньше времени на его вычитку (программисты до 90% времени читают код, а не пишут его). Вы будете быстрее его понимать. Будет меньше шанс на неоднозначную трактовку происходящего. Это все в сумме дает колоссальный эффект.
Простой пример из жизни - это копание в библиотеках с открытым исходным кодом. Когда я лезу в исходники компонентов битрикса, у меня сразу начинает болеть голова. Если же я лезу в исходники компонентов symfony, то их часто читать гораздо легче, несмотря на очевидно бОльшую абстрагированность и сложность.
Важность стандартизации
Стандартизация есть в разных видах деятельности человека, начиная от пищевой промышленности и заканчивая полетами в космос. ГОСТами регламентировался раньше список и процентаж ингридиентов, входящих в состав колбасы. Международными стандартами в области космических технологий регламентируется, например, формат стыковочного модуля.
Возьмите свой телефон. У каждого из вас есть телефон, который просто напичкан разнообразными стандартами - usb, lightning, mini-jack, wi-fi, bluetooth, IPS и т.д. Много их там. Не будь этих стандартов, мы бы не смогли даже информацией обмениваться.
Вот и в разработке вокруг PHP есть попытки что-то стандартизировать с помощью PHP-FIG.
Возьмите PSR-4 - стандарт автозагрузки. Именно по его принципу построен автозагрузчик composer. Благодаря composer вы можете взять практически любую php библиотеку и добавить ее к себе в проект без головной боли. Мне уже сложно представить себе проект, который будет загружать классы как-то иначе.
Возьмите PSR-3 - стандарт логирования. Отличный устоявшийся стандарт, имплементировав который вы сможете сделать мониторинг и логирование любой части своего приложения как с помощью обычных ротирующихся файликов, так и с помощью ELK стека или Prometheus.
На данный момент насчитывается 13 действующих стандартов (всего - 19, если считать еще не принятые). Да, конечно, есть весьма спорные предложения. Но в целом, на мой взгляд, данная инициатива оказала очень серьезное влияние на современный PHP в целом, сделала его экосистему гибкой и одновременно понятной.
KISS DRY YAGNI SOLID GRASP
Наверняка многие из вас слышали эти BuzzWords. Это так называемые принципы (стандарты, методологии, практики, whatever) программирования, которым все должны следовать. Все они являются выражением вашего отношения к коду. Первые три аббревиатуры довольно говорящие:
KISS - Keep it simple, stupid
DRY - Don’t repeat yourself
YAGNI - You aren’t gonna need it

Для большинства очевидно, что код должен быть простым. Мы ведь пишем его для людей. Чем проще код, тем проще его поддерживать. Очевидно. Только вот как достичь этой простоты? Нужны годы и годы тренировок! 🙂
Избегать дублирования кода - очевидно. Вряд ли кому-то захочется исправлять одни и те же ошибки в нескольких разных местах. Просто пишите код так, чтобы в нем не было дублирующихся элементов.
YAGNI - холиварный в некоторой степени подход. С одной стороны, каждый разработчик при создании какой-то фичи пытается предсказать возможные сценарии его развития и использования в будущем, пытается где-то подложить матрасик, а где-то добавить чуть больше, чем нужно. И это очень часто выстреливает и оправдывает себя. С другой стороны - все это требует дополнительного времени и трудозатрат, а если расширять функциональность будет другой разработчик, он может потом очень долго ругаться, что вы не предусмотрели что-то очевидное и добавили какую-то заглушку.
Тут наклевывается популярный пример из мира 1С-Битрикс.
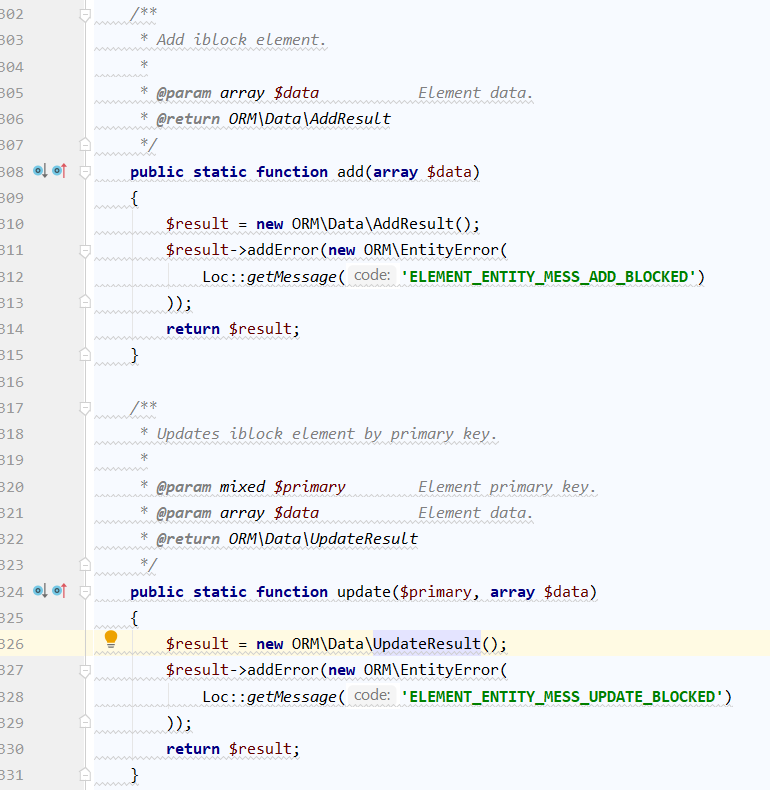
Раньше в этих методах был выброс исключения, а сейчас возврат ошибки, но суть не меняется. Для самой наиболее распространенной сущности в системе - элемента инфоблока, просто не стали реализовывать методы обновления, добавления и удаления. С одной стороны - молодцы, зарелизили модуль, отказавшись от запуска функционала сразу. Вроде бы старое ядро поддерживает. Последовали принципу YAGNI. С другой стороны - разработчикам такой шаг не очень то понравился. Не так давно они обещали что-то выкатить на эту тему. Прошло лет 5 наверно.
Я думаю тут нужно искать какой-то баланс. Не стоит предусматривать всех возможных вариантов развития событий, очень легко будет в этом закопаться. Но и бросать работу на полпути не стоит.
С SOLID все немного сложнее. Эти принципы ввел Роберт Мартин по отношению к объектно ориентированному программированию. Принципы гласят следующее:
- Single Responsibility Principle - принцип единой ответственности. Должна быть только одна причина для изменения класса.
- Open/Closed Principle - принцип открытости-закрытости. Класс должен быть закрыт для модификации и открыт для расширения.
- Liskov Substitution Princple - принцип подстановки Барбары Лисков. Нужно иметь возможность подменить объект на его подтип (наследника) без влияния на корректность исполнения программы.
- Interface Segregation Principle - принцип разделения интерфейса. Лучше иметь много маленьких узкоспециальных интерфейсов, чем один большой интерфейс общего назначения
- Dependency Inversion Principle - принцип инверсии зависимостей. Классы должны зависеть от абстракций. Верхний уровень не должен зависеть от нижнего
Стоит с осторожностью думать и применять каждый из этих принципов, потому что у каждого есть две стороны медали. Но общее правило такое - думай головой, прежде чем что-то делать.
А есть еще GRASP. Вообще, что SOLID, что GRASP - разрабатывались примерно в одно и то же время, но разными людьми (или группами людей). Отчасти можно сказать, что все эти принципы в целом об одном и том же говорят, но с разных точек зрения. У программистов тогда было несколько меньше возможностей для коммуникаций, поэтому они делились всеми возможными находками и практиками в статьях, книгах. GRASP дает нам 9 шаблонов, которым нужно следовать, чтобы писать качественный ООП код, стоит ознакомиться.
Конечно лучше познакомиться со всеми этими принципами. Знать их, несомненно, нужно. Глубокое понимание каждого из них позволит вам разрабатывать по настоящему качественный код. Но также стоит понимать, что бездумное следование всем принципам сразу может привести к невозможности реализации продукта, а также к чрезмерному удорожанию работы над ним. Поэтому поверх всех этих паттернов стоит применять другой, самый главный - «думай головой».
Одно могу сказать совершенно точно. Программисты - большие любители красивых аббревиатур.
Паттерны проектирования
Я периодически общаюсь с разными разработчиками из разных компаний. Однажды один из них спросил меня - сможешь назвать 10 паттернов, которые ты обязательно будешь использовать в своих проектах? Меня очень удивил этот вопрос. А именно - почему 10? Почему не один, или не три? Почему не 23?
Паттерны проектирования - это по сути концентрированный опыт людей, который обрел форму в виде способа оформления кода и его поведения. История знает много случаев использования разных кусков кода, оформленных схожим образом. И история может показать, насколько удобным является тот или иной паттерн.
Изучайте паттерны. Паттерны проектирования, паттерны дизайна приложений. Это все поможет вам лучше писать код.
На меня в свое время очень сильное влияния оказал Dependency Injection. В тот день мир перестал быть прежним для меня. Я тогда наконец понял одну простую истину, которую долго не мог осознать и уложить в голову.
Я не буду останавливаться и детализировать каждый паттерн, по этой теме можно провести не один и не два митапа. Но вы должны изучать паттерны и использовать их в своей ежедневной практике.
Еще раз про стоимость
Прежде чем мы продолжим, я хотел бы напомнить про зависимость стоимости исправления косяка от этапа работ, на котором этот косяк был найден.
Чем раньше косяк был найден, тем лучше будет всем - и ваши нервы будут спокойны, и заказчик будет доволен.
Инструментарий, который предоставляет вам IDE или ваш текстовый редактор в момент набора кода, позволяет найти ошибки на самом раннем этапе, который только возможен. Не стоит недооценивать тот инструментарий, который вы используете в работе. Изучайте возможности своих IDE и текстовых редакторов, настраивайте их на более строгую работу и вы почувствуете прирост в качестве вашего кода (хоть мы пока еще и не научились его измерять).
Важность инструментария

Современный мир предлагает нам огромное количество инструментов. Повар без ножа не сможет приготовить качественное современное блюдо. Ремонтник без перфоратора не сможет сделать качественный современный ремонт. Строитель без башенного крана не сможет построить качественное современное здание. Так и мы с вами без нормальных инструментов не сможем написать качественный код.
Если вы не используете инструментарий, то скорее всего вы менее эффективны, чем другие, а значит на проработку более качественного функционала у вас уйдет больше времени.
Умение использовать инструментарий выгодно отличает наш вид от всех остальных обитателей планеты. Еще более крутой возможностью является способность разрабатывать новый инструментарий под себя. Вот разработчики ежегодно клепают все новые и новые инструменты. О них и поговорим далее.
IDE
Современный разработчик, который пишет качественный код, скорее всего не представляет свою работу без IDE. Мой выбор - PhpStorm.
Можно обустроить среду разработки в VSCode, Sublime, Atom или даже VIM. Все зависит от желания и времени, которое вы хотите на это потратить, но для меня лично самым разумным было все же взять продукт от Jetbrains, потому что это гораздо дешевле и ведет себя она гораздо умнее остальных.
Статический анализ.
Мы уже говорили о таких инструментах как PHP CS Fixer и phpcs. Их можно отнести к инструментам линтинга. Но линтинг сам по себе появился как одно из направлений статического анализа кода. Да что там, сама утилита Lint, имя которой дало название тому самому «современному» линтингу - это программа как раз для статического анализа кода на C.
Есть большое количество направлений статического анализа. Его задача сводится к тому, чтобы не запуская код в исполнение проанализировать его с ног до головы, найти все возможные для такого рода анализа дефекты и вывести эту информацию в виде отчета.
Дальше мы поговорим о наиболее востребованных инструментах статического анализа на данный момент.
Это такие универсальные помощники, которые позволяют работать сразу в нескольких направлениях.
Например, несмотря на то, что в php уже давно завезли статическую типизацию, пока все же несложно стрельнуть себе в ногу. Да и сам язык со своими legacy конструкциями может иногда очень сильно удивлять, возвращая параметры разных типов от одной и той же функции. Этим же очень грешит битрикс. Но благодаря перечисленным выше инструментам, можно очень просто поймать подобного рода проблемы.
У нас довольно часто разработчики натыкаются на такую штуку.
class User
{
public function address(): ?Address
{
return $this->address;
}
}
Допустим, есть метод, который возвращает экземпляр какого-то класса или null, если его не удалось создать. В этом случае нужно добавить nullable typedef, а также phpDoc коммент о возможных вариантах возвращаемых типов.
И когда разработчик начинает такой код использовать, он часто забывает о проверке на null, которая рано или поздно выстрелит. Если не проверить возвращенный результат на null и попытаться вызвать на нем метод класса, то что произойдет? Правильно, ничего хорошего.
При наличии статического анализа очень сложно такую ошибку пропустить.
Или другой пример. Часто разработчикам нужно работать с ассоциативными массивами каких-то объектов, где в качестве ключа используется строка, а в качестве значения - объект какого-то класса. С помощью psalm можно указать, каким должен тип ключа, а каким должен быть тип значения ассоциативного массива.
class User
{
/**
* @psalm-return array<string, Parameter>
*/
public function getAttributes(): array
{
}
/**
* @psalm-return list<string> $arr
*/
public function getAttributeKeys(): array
{
}
}
Дженерики, кстати, тоже можно, если вам надо.
<?php
/**
* @template T
* @psalm-param T $t
* @return T
*/
function mirror($t) {
return $t;
}
$a = 5;
$b = mirror(5); // Psalm knows the result is an int
$c = "foo";
$d = mirror($c); // Psalm knows the result is string
Некоторые из этих инструментов могут нативно встраиваться в IDE. Например, для phpmd достаточно всего пару конфигов включить в PhpStorm, чтобы он заработал. У psalm есть поддержка language server protocol, а значит все его проверки можно точно так же встроить в PhpStorm и не только.
У phpmd есть интересная возможность - замер цикломатической и NPath сложности.
Цикломатическая сложность измеряется очень просто. Внутри каждой функции на каждую управляющую структуру цикломатическая сложность будет увеличиваться на единицу. Она показывает по сути, насколько много у вас управляющих структур в коде. Чем больше - тем хуже. Должно быть не более 8.
NPath сложность - это количество возможных путей развития событий для функции.
function foo($a, $b)
{
if ($a > 10) {
echo 1;
} else {
echo 2;
}
if ($a > $b) {
echo 3;
} else {
echo 4;
}
}
foo(1, 2); // Outputs 24
foo(11, 1); // Outputs 13
foo(11, 20); // Outputs 14
foo(5, 1); // Outputs 23
Чем больше управляющих структур, тем больше таких вариантов развития событий. Чем больше вариантов развития событий, тем сложнее поддерживать функцию. Все просто. Увеличивается экспоненциально. Должно быть не больше 200.
У себя на одном из проектов я нашел вот такие показатели:
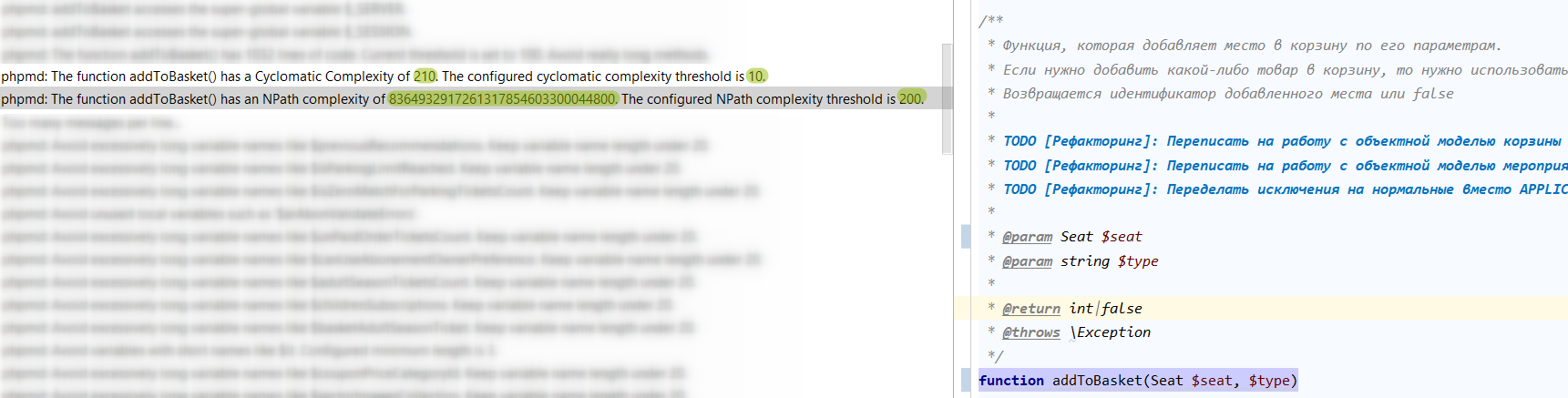
Вы вообще представляете, сколько это? А я вот заморочился, погуглил.
8 нониллионов
364 октиллиона
932 септиллиона
917 секстиллионов
261 квинтиллион
317 квадрилионов
854 триллиона
603 миллиарда
300 миллионов
44 тысячи
восемьсот
Уверен, что многие из вас даже и слов то таких не знали ранее 🙂
Тесты
Давайте на чистоту. Многие ли из вас пишут тесты? 🙂 (в зале 3 руки поднялось).
Ок, давайте так. Я пишу тесты, но очень, очень мало. Тесты могут показаться очень дорогими (особенно когда у вас их нет). Но в реальности они могут сэкономить вам уйму времени. В первую очередь за счет того, что они смогут найти вам кучу ошибок в процессе рефакторинга.
Я сейчас говорю именно о тех тестах, которые можно автоматизировать. А автоматизировать можно все тесты, ну или почти все.
Я уже говорил ранее, что разработчик должен выполнять основную работу по контролю качества, и тесты - неотъемлемая часть здорового контроля качества.
Разработчику крайне желательно разрабатывать модульные (unit) тесты на тот функционал, который он делает. Да, это может занимать 50% времени от всего процесса разработки. Но это инвестиции в будущее. Если вы можете «продать» это время своему заказчику - продавайте. Если не можете - все равно старайтесь писать тесты, хотя бы по минимуму, это время окупится в будущем с лихвой.
Не стоит добиваться 100% покрытия unit тестами, чаще всего это избыточно. Будет достаточно покрыть тестами лишь публичный интерфейс ваших классов.
Помимо модульного тестирования есть еще миллион видов тестирования, и мы конечно не будем про них разговаривать. Но стоит понимать, что вся автоматизация тестирования лежит на разработчике. Никто кроме разработчика не сможет запрограммировать технически грамотный сценарий исполнения кода. Разработчик должен делать и модульные, и функциональные, и приемочные, и smoke, и мутационные тесты. Нужно как можно больше уходить от ручного тестирования в сторону автоматизации, потому что в наши дни возможности автоматического тестирования позволяют избегать ручной работы вообще.
Мне очень жаль тех людей, которые входят в IT через тестирование. Изо дня в день эти люди проходят по сценариям, которые сами же разработали. Это очень скучная работа, и эту работу можно автоматизировать, сэкономить время и деньги. Не надо тестировать руками то, что можно протестировать автоматикой.
Я не говорю, что тестеры не нужны - нет, напротив. Они очень нужны как раз для разработки сценариев, это очень важная творческая работа, которая машине пока не под силу. Но они не должны гонять эти сценарии руками изо дня в день, для этого есть автоматизация, которая сейчас стала дешевле, чем когда-либо.
Вместо монотонного повторения сценариев лучше поручить этим людям задачи по хакингу системы, изучению и улучшению существующих поведенческих сценариев, поиску неочевидных путей исполнения программы и дать им возможности донести эту информацию до разработчиков и владельца продукта.
TDD и программирование через контракты
Разговаривая о тестах, нельзя не упомянуть про TDD - разработку через тестирование. Если вдруг кто не знает - это такой подход, при котором ты сначала продумываешь классы и их публичные интерфейсы, взаимодействие между ними и сразу пишешь тесты на это все. А уже потом, когда публичный интерфейс и взаимодействие задекларированы, нужно приступать к имплементации, постепенно реализуя программу таким образом, чтобы она проходила тесты и удовлетворяла требованиям.
Это грамотный подход, поскольку он позволяет сразу же быть уверенным в корректности ожиданий.
Но мне больше нравится называть этот подход контрактным программированием (хотя в интернетах контрактным называют другой подход к программированию).
В PHP контрактом каждого класса является его публичный интерфейс. При контрактном подходе к программированию мы сначала фиксируем этот публичный интерфейс, в первую очередь думаем о нем, а только потом уже думаем о тонкостях реализации внутри. Такой подход позволит вам сконцентрироваться в первую очередь не на том, что у вас внутри класса, а на том, как этот класс будет взаимодействовать с другими классами. Это очень важно.
Сначала фиксируем контракт - интерфейс, его публичные методы, их сигнатуру, возвращаемые значения, возможные исключения. Затем мы продумываем другие интерфейсы схожим образом и продумываем взаимодействие между ними. Разница между TDD и контрактным программированием в действительности только в том, что в случае с TDD все это выливается в форму тестов, а при контрактном программировании - нет.
Основной же смысл TDD и контрактного программирования крайне прост и банален - сначала надо думать, а потом делать. TDD переводит эту идею в плоскость реализации, т.к. заставляет сразу написать некоторое количество кода, материализуя его.
И еще раз - моя трактовка контрактного программирования тут отличается от общепринятой. В php мире есть один единственный фреймворк для «настоящего» контрактного программирования, и это совсем не то, чем стоило бы заниматься в продакшене на подавляющем большинстве проектов. Специально не буду на него ссылки приводить, но его разработал Евгений Лисаченко, а он знает толк в извращениях с php. Кому интересно - тот найдет.
Code Review
Для многих практика Codereview стала настолько привычной, что кажется не нужно уже это обсуждать. Но не везде все так радужно. Если у вас до сих пор нет Codereview, то скорее всего уже пора его внедрить.
Codereview - это отличная практика для контроля качества вашего кода. Благодаря Codereview вы получаете сразу несколько плюшек:
- еще один слой контроля качества кода
- sharing знаний между разными членами команды, а иногда и между разными командами
- площадка для коммуникаций и холиваров
Желательно построить процесс ревью таким образом, чтобы в нем принимали участие разные члены команды. Это позволит вам быстрее обмениваться опытом в команде. Если процесс ревью завязан на одного человека - это не очень хорошо, т.к. повышаются риски задержек. На небольших проектах с небольшими командами это может быть оправдано, но на более крупных уже нет.
Codereview крайне желательно проводить в интерфейсе IDE. Это позволяет вам видеть контекст задачи, иметь возможность навигации по коду и много много чего еще.
Жаль что у продуктов Jetbrains нет встроенной интеграции с нашим горячо любимым Gitlab (хотя совсем недавно появился плагин, правда пока сыроват)
Каждый раз на ревью стоит думать о напарнике, который будет это ревью делать. Есть четкая зависимость времени, требуемого для ревью, от количества измененного в PR кода. Чем больше PR - тем быстрее он пройдет проверку. Казалось бы, должно быть совсем наоборот, но нет. Чем больше PR, тем меньше хочется разбираться во всех хитросплетениях. И что самое печальное - тем хуже на выходе итоговое качество, потому что в итоге ревьюер смотрит сквозь пальцы на ваш код.
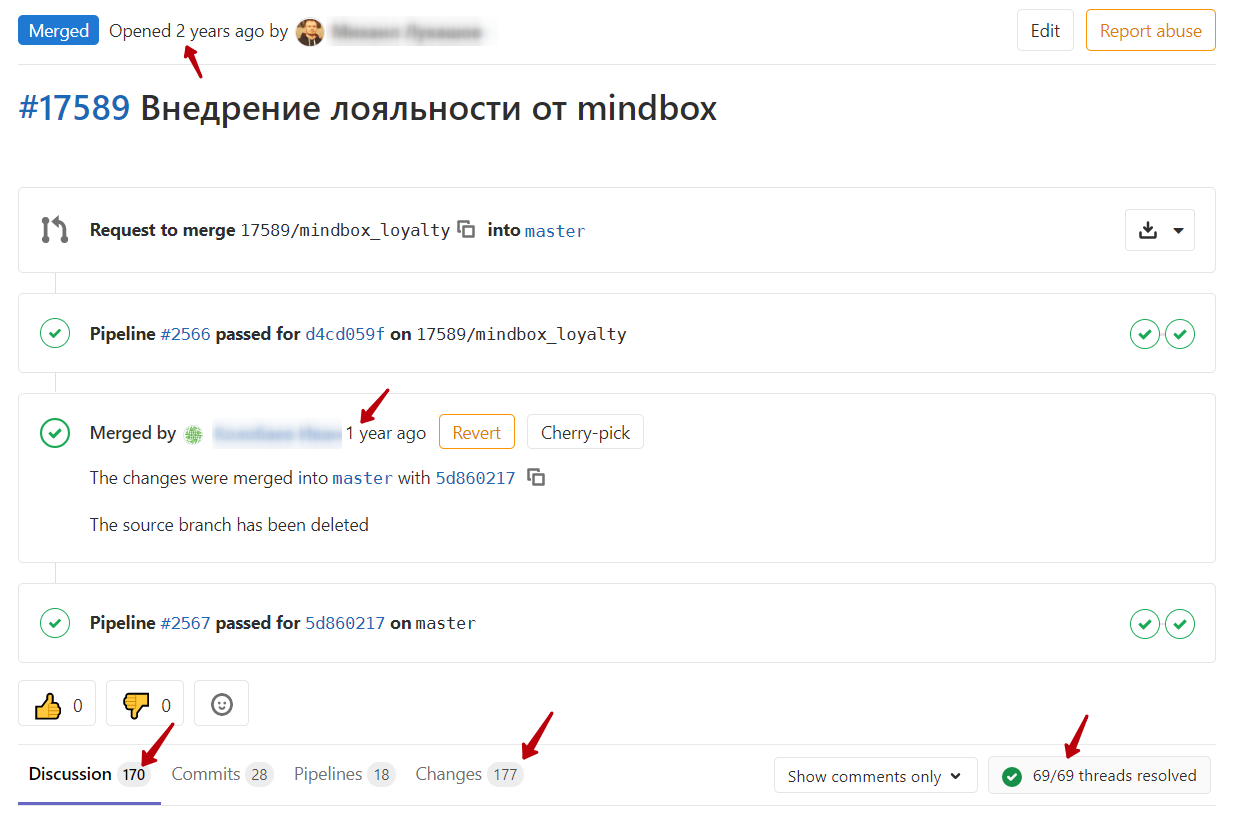
Мы конечно стараемся не профакапить, но даже на таком количестве изменений уже крайне сложно делать ревью. Выход - делать инкрементальные ревью по маленьким кусочкам.
Постоянный рефакторинг
Разработчики не умеют сразу писать хороший код. Это данность. Лишь со временем мы понимаем, что и как в реальности должно работать. Если вы работаете над «живым» проектом, который постоянно развивается, у вас появится постоянная необходимость добавлять какую-то новую функциональность в те места, в которых ее раньше не было.
Не бойтесь рефакторить. Процесс разработки - это постоянная череда внесения новых фич, исправления старых багов, выполнения рефакторинга старого кода. Без регулярного рефакторинга загнется любой проект. Каждодневный рефакторинг - это то, за что программисты деньги получают.
Сюда же можно отнести и технический долг. Каждый раз, когда вы впопыхах разрабатываете какую-то новую фичу по воле заказчика, скорее всего вы пытаетесь где-то срезать углы, обойти свою архитектуру каким-то не совсем корректным, но определенно быстрым решением. Это может быть очень полезно. Но в таких случаях не забывайте сразу же добавлять в свой трекер задачу на исправление этого технического долга. Как только появится время и возможность - лучше заняться исправлением, чтобы он не накапливался. Это очень сложно применить в аутсорсе, но в продуктовых компаниях это очень даже работает.
Технический долг и обильные костыли в архитектуре могут привести к невозможности дальнейшего развития проекта, либо к серьезному удорожанию этого процесса. Заказчик должен понимать это.
Документация
Неотъемлемой частью любого качественного проекта является наличие документации. Актуальной документации. Если мы говорим про код, то это, естественно, phpDoc. Мне до сих пор встречаются разработчики, считающие себя уровнем middle, которые даже не слышали о phpDoc, хотя казалось бы …
Если вы еще не, то зайдите на сайт phpDoc, хотя бы поверхностно ознакомьтесь с документацией. Ваша жизнь больше никогда не будет прежней. Благодаря phpDoc у вас нет необходимости выходить из IDE, чтобы найти описание подзабытой функции php. Благодаря phpDoc вы можете назначать описания своих классов и методов, их сигнатур, и тут же просматривать их в IDE. Это чертовски удобно.
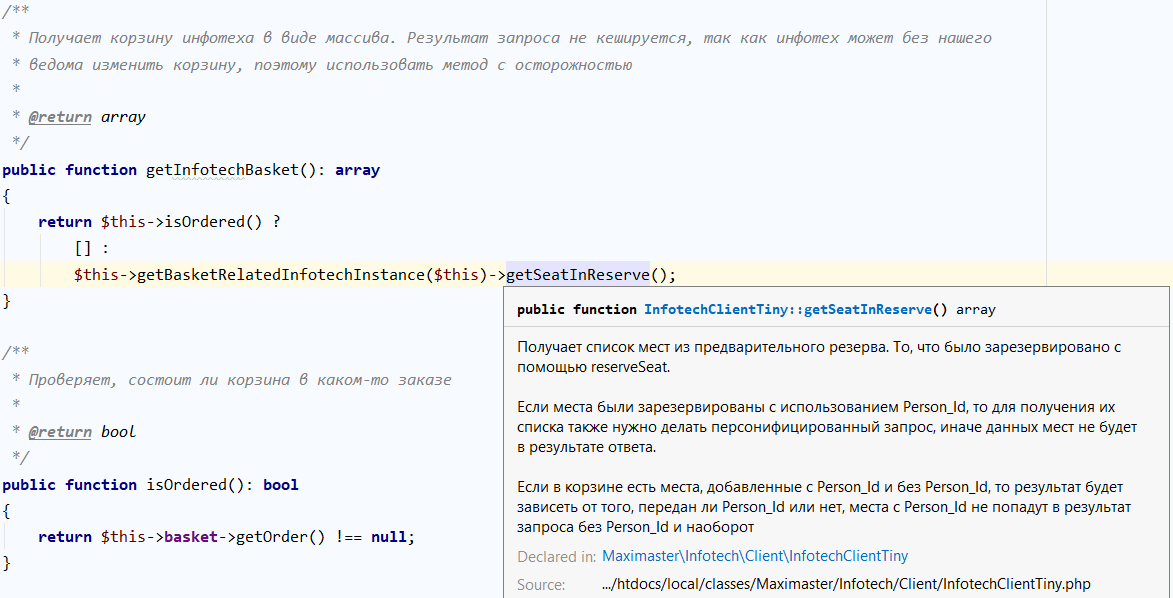
Но с документацией есть одна большая проблема - ее нужно обновлять. Рефакторинг - это то, за что программисты получают деньги. Но не забывайте при рефакторинге еще и документацию к коду менять, это очень важно.
Pipeline - всему голова
Чем больше я занимаюсь разработкой, тем больше мне становится ясно, что программисты - это такие большие дети, которые постоянно чему-то учатся. И часто их некому бить по рукам за не очень правильные решения. А когда такой человек все же есть, велик риск, что ребенок обидется и будет еще хуже.
Было бы очень здорово, если бы был какой-то робот, которого нельзя обойти. Такой строгий дядя-робот, у которого нет эмоций, который всегда знает, как должно быть правильно, и которого никак нельзя обойти.
В последнее время набирает популярность мнение, что наиболее важной штукой в процессе разработки является Continuous Integration Pipeline. И я сторонник этого мнения. Я считаю, что Pipeline должен быть настолько строгим, насколько это вообще возможно. В процесс автоматизированного тестирования приложения должно входить столько проверок, сколько нужно для обеспечения максимального уровня качества продукта.
Что такое pipeline по большому счету? Это набор скриптов, который должен выполниться успешно целиком. В противном случае pipeline не успешен.
- codestyle check
- static analysis check
- unit tests
- mutation tests
- acceptance tests
Нет никакого смысла даже к ревью приступать, если все проверки не прошли успешно, потому что ревьюер будет тратить свое время на поиск тех проблем, которые отлавливает автоматика. А зачем тратить время ревьюера на поиск ошибок в codestyle? Не понятно.
Поэтому, если у вас еще нет CI - самое время его внедрить. Это страж, который стоит на стреме и не пропускает плохой код.
Архитектура
Возможно кто-то ждал этого пункта с самого начала, но я оставил его на самый конец намеренно, потому что до него должны добраться самые выносливые и сильные 🙂
Этот пункт - последний в моем списке, но он далеко не последний по значимости.
Я заимствовал этот слайд (как и парочку других 🙂) из доклада Marco Pivetta про агрессивный PHP QA. Здесь довольно наглядно расставлены приоритеты, которым нужно следовать при проработке системы контроля качества.
Основой всего являются требования. Если невозможно собрать качественные требования, то будет очень сложно проработать качественное решение.
Архитектура решения - это вторая по значимости штука.
Что мы обычно понимаем под архитектурой приложения? По сути - это набор соглашений между разработчиками в команде, которым нужно следовать при разработке проекта.
Парадокс. Заказчику обычно абсолютно все равно на архитектуру, даже несмотря на то, что архитектура является ключевым аспектом для успешности его продукта в догосрочном периоде.
Я в последнее время стараюсь очень много времени уделять теории, которая крутится вокруг архитектурных решений в PHP приложениях. О некоторых поведаю
Семантика
Первое, о чем стоит договориться разработчикам между собой - это то, что я называю семантикой.
Семантика в html - это способ указать кому-то, что вот в этом html элементе в действительности находится какое-то значимое высказывание, а вот тут - таблица.
Подобно этому семантика в PHP архитектуре - это способ дать разработчику понять, что вот эта группа классов отвечает за работу с СУБД, вот эта - за работу с сущностями системы, а вот эта - с чем-то еще.
Вам стоит договориться с командой, какие возможные сущности вам понадобятся, и где в файловой системе должны находиться файлики, которые отвечают за работу с той или иной штукой. У каждого класса в проекте есть определенная роль. В последнее время я наиболее часто вижу следующее разделение:
- Сущность (Entity). Обычный класс, который является проекцией какой-то реальной сущности в понятиях вашей системы. Важно, чтобы любая сущность могла быть уникально идентифицирована с помощью какого-то идентификатора. Сущности обычно где-то хранятся (в СУБД, в REST API, в файлах и т.д.)
- Коллекция (Collection). Класс, который предоставляет интерфейс работы с набором нескольких сущностей и обычно содержит методы для обработки этой коллекции, итерации по элементам коллекции, агрегации каких-то данных о коллекции
- Объект-значение (Value Object). Обычный класс, который инкапсулирует в себя какие-то данные, которые можно идентифицировать на основании этих же данных. Не имеют идентификатора и обычно иммутабельны. Часто входит в состав сущности
- Репозиторий. Класс, который позволяет извлекать данные из хранилища и записывать их туда. Он должен работать как in-memory хранилище и предоставлять интерфейс для получения сущностей по каким-то критериям (по id, по фильтру, с применением сортировки и т.д.). Может возвращать сущность (при одиночном запросе в хранилище) или коллекцию (при получении нескольких сущностей)
- Сервис. Обычный класс, который умеет делать какую-то полезную работу над объектами других классов. На вход в конструктор обычно принимает зависимости, требуемые для обработки каких-то данных и имеет один или несколько методов для выполнения какой-то работы. Не содержит состояния и содержит только «чистые» методы
- DTO. Простой объект без логики, который позволяет перебросить структурированный набор данных из одного слоя приложения в другой
- …
Есть еще много семантических «ролей». В проекте нужно обеспечить возможность прозрачного детектирования той или иной семантической роли любым участником проекта.
Дерево файлов проекта
Помимо этого вам нужно договориться, где хранить всякие инфраструктурные штуки (конфиги, миграции и т.д.), где хранить вьюшки (если они у вас вообще есть), где расположить контроллеры, тесты, консольное приложение. На каком уровне будет документ-рут. Обычно, все эти вопросы уже решены в том фреймворке, который вы используете. Но дальше вам нужно решить, как вообще поступать с бизнес-логикой.
Сюда же стоит отнести и способ организации репозитория. В настоящий момент существует два основных подхода - monorepo и multirepo. В первом случае весь код, который нужен для проекта, находится в одном репозитории. Во втором - в разных. В большинстве случаев удобнее будет использовать monorepo, банально чтобы избежать накладных расходов со сборкой всего и вся воедино во всех окружениях (dev, test, prod).
Domain Driven Design
Идея хоть уже и не новая совсем, но очень круто набирает популярность в php. Люди успешно использовали DDD еще тогда, когда я в мире php пешком под стол ходил.
DDD - это способ семантического взаимодействия с бизнесом. Благодаря DDD вы можете наладить прямой контакт между разработчиком и бизнесом, заставив их разговаривать на одном языке и более того, можно заставить разработчиков писать код на языке бизнеса.
Почти весь код, который сейчас пишут php разработчики, связан с бизнесом. Поэтому и все правила должны диктоваться бизнесом, исходить из него. Все формулировки, термины, используемые в коде, все события и сценарии, протекающие в рантайме - все это должно подчиняться требованиям того бизнеса, на который мы работаем.
Имплементация DDD в коде подразумевает разбиение проекта на бизнес-контексты и делает акценты на взаимодействии между ними. Внутри каждого контекста есть один или несколько семантических ролей типа «Агрегат», вокруг которого крутится вся бизнес-логика. Каждый агрегат инкапсулирует внутри себя одну или несколько сущностей, где одна из сущностей (или какая-то собирательная виртуальная сущность) является корневой, от которой строятся дальнейшие логические цепочки. Каждая сущность состоит из скалярных значений и Value Object’ов. Разные контексты общаются между собой с помощью событий предметной области или с помощью публичного интерфейса агрегатов. Для выполнения сложной бизнес-логики задействуются службы предметной области, а для отправки информации в другие контексты используются события предметной области.
Очень крутая концепция. Рекомендую всем хотя бы поверхностно почитать, посмотреть доклады на эту тему. Хорошо расставляет все по местам. А потом обязятельно почитать Эванса и Вернона, если есть возможность - в оригинале, русский перевод просто ужасен.
CQRS
Очень часто вместе с DDD применяется подход, который позволяет разделить все операции над агрегатами на два разных потока - чтение и запись. При этом потоки чтения и записи обычно еще выносят в асинхронные процессы, потому что в больших системах один из каналов или сразу оба могут быть чересчур нагруженными.
В коде этот подход выражается следующими семантическими блоками:
- Запрос. Обычный класс, который содержит всю информацию, необходимую для выполнения какой-то задачи на чтение данных.
- Обработчик запроса. Класс, который принимает на вход запрос, выполняет этот самый запрос с помощью репозитория и возвращает ответ
- Команда. Обычный класс, практически идентичный запросу. Содержит всю информацию, которая необходима для выполнения команды
- Обработчик команды. Класс, который принимает на вход команду и выполняет ее
Запросы и Команды обычно идут до обработчика через какую-то асинхронную систему (очередь, шина данных) и выполняются в асинхронном режиме.
Event Sourcing
Есть некоторый класс систем, в которых важно не потерять ничего. Например, когда в одну и ту же сущность могут внести изменение разные виды пользователей с разными привилегиями, часто нужно понимать - почему именно вот этот пользователь это сделал, каков был его мотив и в рамках какого сценария он это сделал. Получается, нужна какая-то история изменения этой сущности.
Есть способ построения архитектуры, при котором любое изменение в состояние приложения вносится с помощью событий. Все события с каждым изменением хранятся в каком-то хранилище. Чтобы воспроизвести состояние системы в любой момент истории, достаточно «проиграть» все события от начала проекта и до нужного момента времени.
Наиболее известным решением для построения подобных систем является Apache Kafka.
С применением этого подхода к архитектуре очень легко стрельнуть себе в ногу, поэтому прежде чем строить системы по этому принципу - стоит более глубоко погрузиться в тему.
Слоеная, луковая, чистая, гексагональная архитектура, порты, адаптеры, вот это все.
Опять же, часто в контексте DDD используется разделение приложения на слои. Обычно это доменный, инфраструктурный слои, а также слой приложения плюс их различные вариации. Идея заключается в том, чтобы четко разложить ответственность каждого семантического класса по этим слоям и организовать между ними четкие правила взаимодействия.
На доменном слое располагается бизнес-логика. На инфраструктурном слое находятся реализации репозиториев и сервисов, взаимодействующих с API, СУБД, файлами и т.д. А на слое приложения - контроллеры, представления.
Очень много вариаций придумало сообщества для определения одного лишь факта - уменьшения связности кода.
Это разделение по слоям в реальности нужно лишь для того, чтобы уменьшить связность между разными частями приложения. А уменьшение связности нужно для того, чтобы упростить реиспользование кода и его рефакторинг. Меньше связей - проще рефакторинг и замена подкапотностей.
Но одного разделения мало. Надо же это как-то разделение контролировать. Не на ревью же это делать? Но и тут нам поможет статический анализ.
Deptrac
# depfile.yml
paths:
- ./examples/ControllerServiceRepository1/
exclude_files: ~
layers:
- name: Controller
collectors:
- type: className
regex: .*MyNamespace\\.*Controller.*
- name: Repository
collectors:
- type: className
regex: .*MyNamespace\\.*Repository.*
- name: Service
collectors:
- type: className
regex: .*MyNamespace\\.*Service.*
ruleset:
Controller:
- Service
Service:
- Repository
Repository: ~
deptrac позволяет описать правила разделения на слои с помощью простого конфига. Конфиг читается очень легко, в нем находятся простые правила, описывающие два факта - где искать классы нужных слоев и в каком направлении эти классы могут быть связаны.
После запуска мы получаем отчет, в котором наглядно можно увидеть, что и от чего зависит, в каком направлении.
Структуризация классов по модулям
Мои коллеги раньше спрашивали меня - а как лучше структурировать классы в проекте? Я не мог раньше ответить на этот вопрос, но затем озаботился и удалось найти исследования по этой теме. Я нашел упоминания о четырех возможных подходах, названия которых говорят сами за себя.
- Package by Framework
- Package by Type
- Package by Layers
- Package by Feature
By Framework - это способ распределения кода по тем принципам, которые заложил фреймворк (CMS, Библиотека, etc). Если сказано автором фреймворка, что контроллеры надо хранить вот тут - значит они и лежат вот тут.
By Type - когда вы все семантические единицы храните в одном месте. Контроллеры - в неймспейсе контроллеров. Сущности - в неймспейсе сущностей. DTO - в неймспейсе с DTO и т.д.
By Layers - способ разделения кода по слоям. Это отсылка как раз к Hexagonal Architecture. Весь код, относящийся к доменному слою - хранится в одном неймспейсе, а весь код инфраструктурного слоя - в другом.
Все эти варианты сейчас - «прошлый век». Когда мы разрабатываем что-то, то работаем в рамках одной или нескольких фич. Удобнее будет, если все необходимое для работы над каждой фичей будет лежать недалеко друг от друга, тогда не придется лазать по директориям всего проекта, особенно когда файликов много. Меняя код, распределенный по слоям, по типам или по правилам фреймворка, приходится бегать по файловой системе туда-сюда.
Поэтому сообщество идет к более компонентному подходу (by Feature). Идея заключается в том, чтобы сконцентрировать группу классов, объединенных одной фичей, в одном месте. В контексте DDD можно группировать весь код вокруг Агрегатов, поскольку каждый агрегат сам в себе по сути и является отдельно взятой фичей. Если у вас нет DDD - не страшно. выделяйте обособленный кусок функциональности и работайте с ним как с фичей.
И на эту структуру очень хорошо ложится тот же Deptrac. Вы сможете отслеживать взаимосвязи между фичами, а не между слоями, что будет гораздо более ценной информацией как для вас, так и для бизнеса.
Architecture Decision Record
Когда принимается какое-то архитектурное решение, не всегда ясны мотивы этого решения. Некоторые решения принимаются единолично архитектором, но нигде не фиксируются формально. Они просто есть, но им нужно следовать. Но как им следовать, если они нигде не зафиксированы?
Когда в команде есть несколько опытных коллег, то скорее всего они принимают архитектурные решения вместе. Результатом такого решения становится договоренность между членами команды, с которой каждый из них согласен. Но этот факт обычно оговаривается на словах, либо зафиксирован в недрах документации, которую никто не обновляет. А документация, как правило, обновляется плохо.
В проектах с долгой историей довольно сложно проследить ход мысли архитекторов. Решения принимаются, архитекторы меняют друг друга, каждый архитектор жалуется на решения предыдущего, предлагая каждый раз все переделать. Часто это происходит из-за того, что архитектор может не понимать всех причин, по которым было принято то или иное архитектурное решение. Было бы здорово иметь историю принятия таких решений.
Architecture Decision Record - это инструмент, который позволяет решить обозначенные проблемы. Это обычный текстовый документ, который фиксирует решения и мысли в специально структурированном виде. Выглядит он примерно так:
Прямо в репозитории со своим проектом создайте директорию, в которой будет набор Markdown’ов. Каждый документ, который находится в master ветке - это принятое решение. Чтобы такой документ попал в master ветку, нужно его сначала завести и описать в следующем формате:
- Заголовок
- Решение, которое принимается
- Статус решения
- Контекст принятия решения
- Последствия принимаемого решения
В этих разделах вы описываете то, какое решение вы принимаете, почему вы так решили и к чему это приведет. Затем создаете PR и предлагаете каждому члену команды принять, либо отклонить это решение (с пояснением и предложением исправить/дополнить). И так до тех пор, пока каждый не согласится со всем. Это позволит и получить согласие от каждого члена команды с решением, и вести историю таких решений, и вводить новых людей в курс дела по архитектуре. Простой и при этом мощный инструмент.
Выводы
Писать чистый код - это очень не просто. Для этого нужны годы и годы практики. Для этого нужно знать и понимать много вещей. За это программисты деньги и получают. Мало информации тут быть не может. За то время, пока существует наша отрасль, количество этой информации уже стало большим, и тенденций по уменьшению её объёма нет, скорее наоборот. Поэтому наша с вами задача заключается в том, чтобы:
- Изучить все то, что предлагает нам история IT
- Переварить это все и структурировать в голове как у себя, так и у своих подопечных
- Сделать так, чтобы новичкам не приходилось тратить 10 лет своей жизни на изучение и знакомство с этими аспектами
- Чтобы каждый новичок мог делать код, хороший, чистый, качественный, не прилагая к этому титанических усилий